Self-serve feature platforms: architectures and APIs
The last few years saw the maturation of a core component of the MLOps stack that has significantly improved the ML production workflows: feature platforms. A feature platform handles feature engineering, feature computation, and serving computed features for models to use to generate predictions.
LinkedIn, for example, mentioned that they’ve deployed Feathr, their feature platform, for dozens of applications at LinkedIn including Search, Feed, and Ads. Their feature platform reduced engineering time required for adding and experimenting with new features from weeks to days, while performed faster than the custom feature processing pipelines that they replaced by as much as 50%.
This post consists of two parts. The first part discusses the evolution of feature platforms, how they differ from model platforms and feature stores. The second part discusses the core challenges of making feature platforms self-serve for data scientists and increase the iteration speed for feature engineering.
If you’re already familiar with feature platforms, you might want to skip Part I. To see the a list of public feature platforms referenced for this post, see Comparison of feature platforms.
Part I. Evolution of feature platforms
The need for feature platforms arose when companies moved from batch prediction to online prediction. Without a feature platform, online prediction at scale for many use cases would be hard, if not impossible. This doesn’t mean that a feature platform can’t support batch prediction. For many companies, a feature platform can be used to support both batch and online prediction.
A challenge for most online prediction use cases is latency, which results from 3 types of latency (excluding network latency):
- Feature computation latency: time it takes to compute features from raw data. If a model only uses features that have been precomputed, this value will be none during inference.
- Feature retrieval latency: time it takes for the prediction service to retrieve computed features needed to compute prediction.
- Prediction computation latency: time it takes for a model to generate a prediction from computed features.

Prediction computation is relatively well-researched, and many tools have been developed to optimize it. Feature platforms are designed to optimize feature computation and feature retrieval, not prediction computation latency.
Feature platform vs. feature store
Since the industry is still new, people might have different opinions, but generally, a feature store is part of a feature platform. The main goals of a feature store are:
- Reduce feature retrieval latency
- Store computed features for reuse to reduce computation cost: multiple models that need the same feature should be able to reuse that feature without redundant computation.
In its simplest form, a feature store is a key-value store that stores computed features in-memory. Common key-value stores include DynamoDB, Redis, Bigtable. In its moderately more complex form, a feature store also handles persisting feature values on disk so that they can be used for training, ensuring the train-predict consistency.
Feature platforms handle both feature retrieval and feature computation. The most notable examples of feature platforms are Airbnb’s Chronon (previously Zipline) and LinkedIn’s Feathr (open source).
Feature stores like Feast, Amazon SageMaker Feature Store, and Vertex AI Feature Store do not handle feature computation, and therefore, are not feature platforms.
Feature platform vs. model platform
As online prediction use cases mature, we see more and more companies separating their feature platform from their model platform, as they have distinct responsibilities and requirements.
Model platform
A model platform concerns how models are packaged and served. It usually consists of three major components:
- Model deployment API: how to package a trained model (e.g. serialized, versioned, tagged) with necessary dependencies. In many cases, trained models can also be automatically optimized (e.g. quantized). Ideally, model deployment should be self-serve – data scientists should be able to deploy models by themselves instead of handing them off to engineering teams.
- Model registry (model store): responsible for storing and versioning a packaged model to be retrieved for predictions.
- Prediction service: responsible for retrieving models, allocating and scaling resources to generate predictions and to serve them to users.
Note: Experimentation can be considered the fourth piece of the model platform. For many companies, model testing (shadow, A/B testing) is handled by a separate team. However, it’d be a lot easier if data scientists can configure experimentations to evaluate their models in production, and the prediction service can route traffic based on the experimentation configurations.
Feature platform
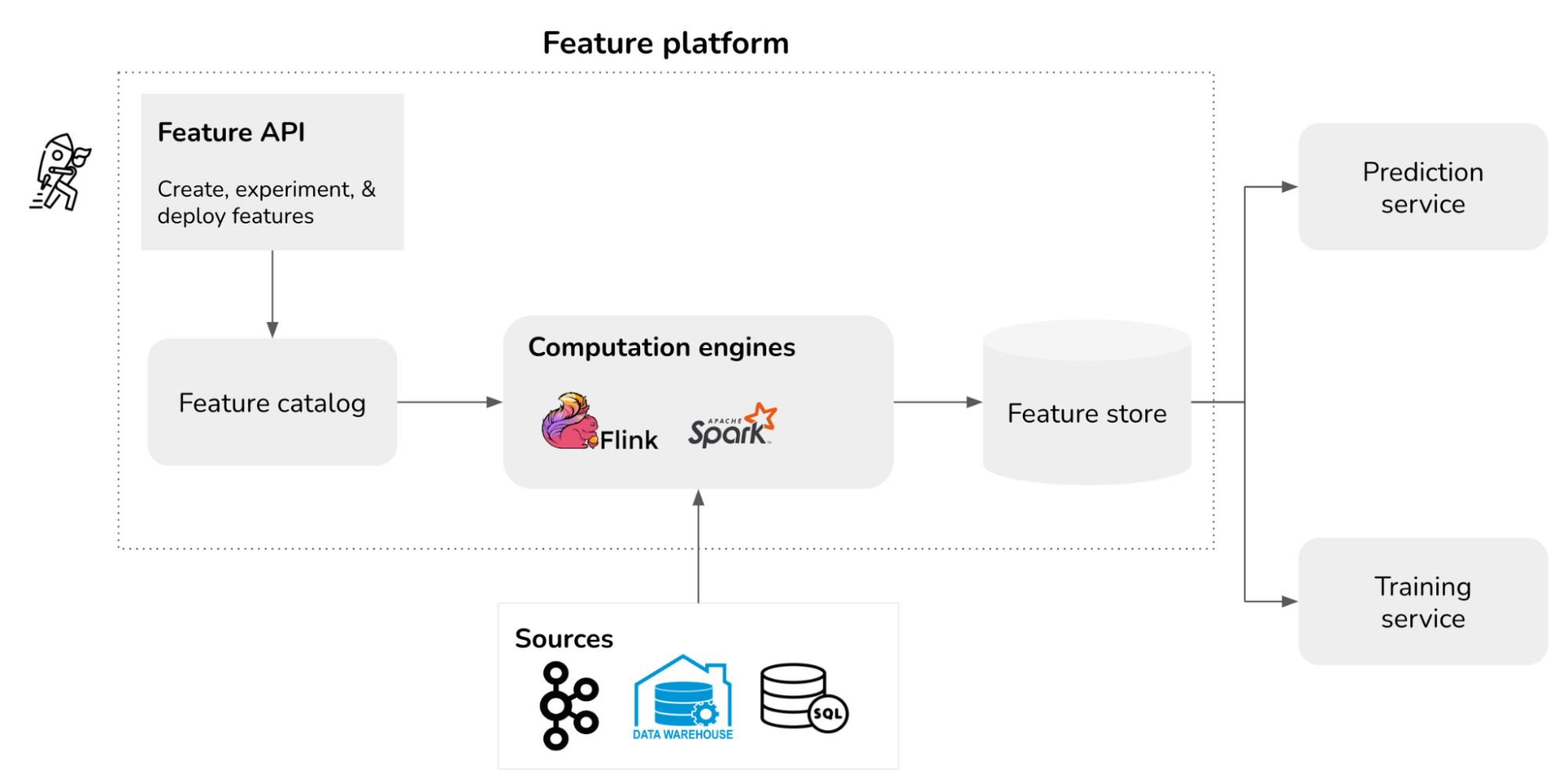
A feature platform concerns the whole feature engineering workflow. A feature platform consists of the following components:
- Feature API: how data scientists can create, deploy, discover, and experiment with features. Ideally, feature engineering should be self-serve for data scientists, so that they can do their job without having to pair with or wait for data engineers. This can also free data engineers to focus on more interesting work.
- Feature catalog: a catalog to store feature definitions and metadata, so that users can discover and share features.
- Computation engines: the engines used to compute features, e.g. Spark, Flink.
- Feature store: physical storage of computed feature values.
For a company at a reasonable scale, a feature platform is much harder to build than a model platform for the following reasons.
- Cost. Companies have repeatedly told me that the majority of their infrastructure cost is in feature computation and storage. For an ecommerce or a fintech company of about 10M accounts, feature computation for their anti-fraud use case alone can be between a million and 10 million USD a year.
- Cross-team collaboration between data engineers and data scientists. For use cases in computer vision and NLP, features can be computed using a small number of data sources. However, for use cases with tabular data like fraud, recommender system, ETA, dynamic pricing, etc. features are computed from many sources, which require the feature platform to work much more closely with the data platform compared to the model platform.
- Iteration speed. Given that there are many features for any given model, the need for a platform that enables data scientists to iterate on features quickly is important. Given the right infrastructure, the number of features can grow rapidly. We’ve seen the total number of features for a company growing 2x to 10x over the last 3 years, up to 10,000s features.
Types of features a feature platform can compute
For a feature platform to handle feature computation, it’s important to consider what types of computation it can, or should handle. In general, companies divide feature computation into three different categories:
- Batch features
- Real-time (RT) features
- Near real-time (NRT) features
Each of these feature types require different ways to ingest data and different computation engines. Which feature types you need depend on your use cases, business logic, and latency requirements. We’ve seen an increasing number of use cases that require all three feature types. For a detailed analysis of these three different feature types, see Appendix: Batch features vs. real-time features vs. near real-time features.
| Feature type | How | Example compute engines | Example | Latency | Pros | Cons |
| Batch | Precomputed in a batch process | Spark | Daily computed embeddings | Hours, days | Easy to set up |
|
| NRT | Precomputed in a streaming process | Flink, Spark Streaming | Avg transaction value over last 30 mins | Seconds* |
|
Companies think it's harder to set up |
| RT | Computed at time of prediction | - | If transaction value > $1000 | < 1sec |
|
Doesn't scale |
* The latency gap between real-time and near real-time features is closing, as near real-time feature computation is becoming faster as better streaming technology matures.
Not all feature platforms can or should handle all feature types. For example, Robinhood’s feature platform, as of 2021, only handles batch features and real-time features. They’re not yet supporting near real-time features, but it’s on their roadmap.
Real-time features might be sufficient for a smaller scale and simple online prediction use cases. However, it’s hard to optimize for latency and cost for real-time features, especially as the prediction traffic fluctuates or grows, and the complexity of features increases. As a company onboards more online prediction use cases and their online feature space grows, supporting near real-time features is essential.
A year ago, I discussed in the post Real-time machine learning: challenges and solutions that most companies moving batch prediction to online prediction do so in two major steps:
- Re-architect their prediction service to support online prediction, still using only batch features.
- Re-architect their feature platform to support streaming features.
Since then, I’ve observed this pattern at multiple companies. For example, Instacart discussed their two-step transitions from batch to online prediction in Lessons Learned: The Journey to Real-Time Machine Learning at Instacart. DoorDash’s head of ML infra Hien Luu advised that, in the journey to build out an ML platform, companies should start small, and DoorDash started with their high throughput, low latency prediction service Sybil (2020). After that, they introduced their feature platform Riviera (2021), then Fabricator (2022).
Part 2. Self-serve feature engineering
Challenge: slow iteration speed for streaming features
Workflows for batch features are well understood – data scientists are familiar with the process of using tools like pandas, Spark. Workflows for streaming features, however, still have much to desire for.
Even the household-name companies with high MLOps maturity we’ve interviewed have challenges with the iteration speed for streaming features. The long iteration cycle for streaming features discourages data scientists from working with them, even if these features seem to show a lot of promise. One of their data scientists told us that: “Instead of spending a quarter struggling with a streaming feature, I’d rather experiment with 10 batch features.”
We categorized the causes for the slow iteration speed into two buckets: lack of data scientist-friendly API, and lack of functionality for fast experimentation.
1. Feature API
Streaming is a concept from the infrastructure world. True streaming engines like Flink are built on top of JVM, a place most data scientists aren’t acquainted with. This fact is, unfortunately, often dismissed by the infra engineers who build feature platforms.
Scala or Scala-inspired interface
We’ve seen early generations of feature platforms adopt a Scala or Kotlin interface. The image below is just some examples. When I ask infra engineers if they find Scala API to be a challenge for users to adopt, the answer is usually no – “data scientists are engineers, they can learn a new language.” When I ask the same questions to data scientists, the answer is usually yes. Many companies that have adopted a Scala interface.

SQL interface
Our impression, from talking with our colleagues in streaming, is that there’s a consensus that SQL is inevitable. Almost all streaming engines have introduced their own SQL interfaces (see Flink SQL, KSQL, Dataflow SQL). Some feature platforms, therefore, adopt SQL.
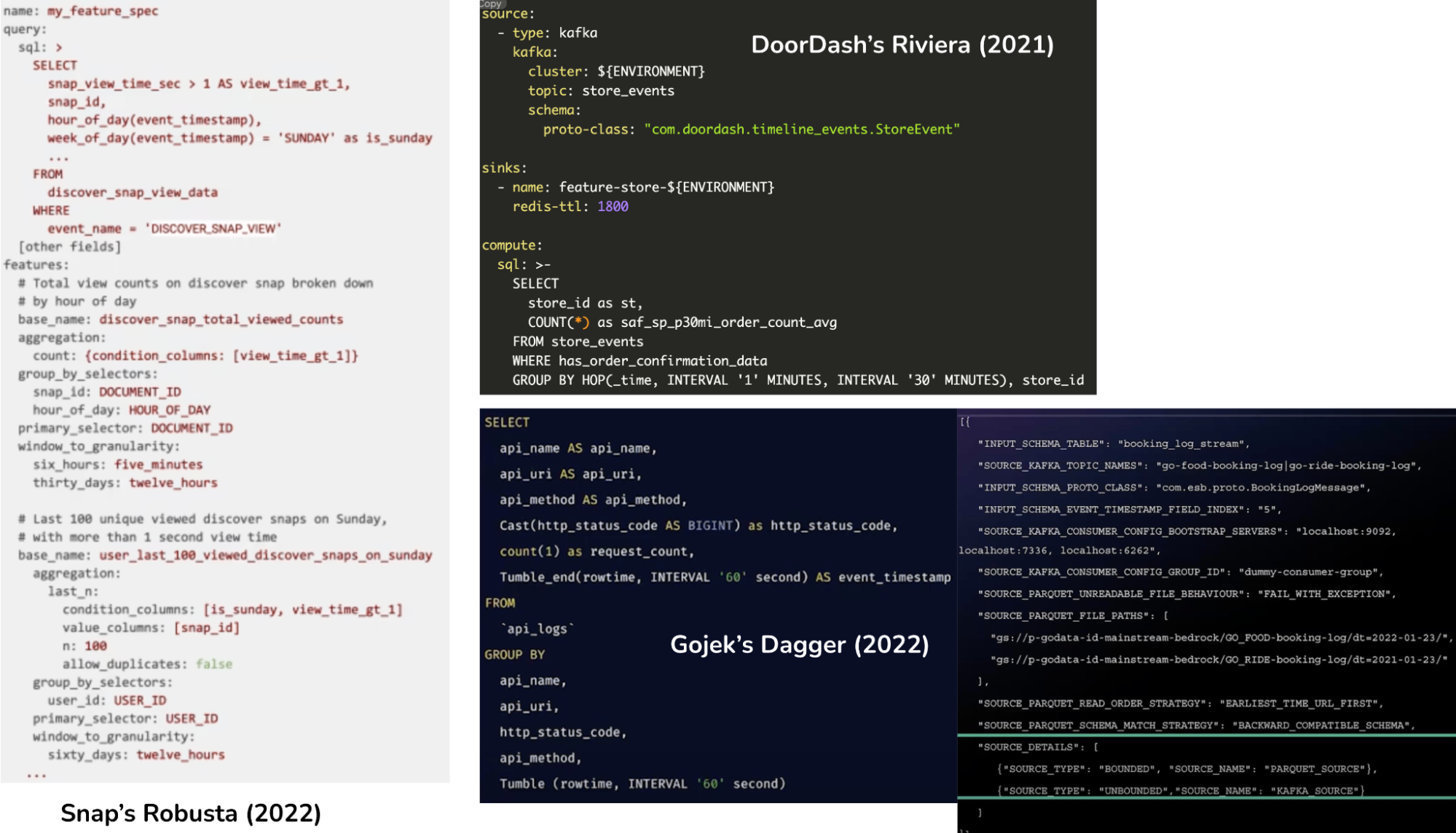
If a company goes with SQL, the next question is which SQL dialect to support. Some companies use Flink SQL directly as their feature API. In the image above, DoorDash seems to be using Flink SQL. Snap uses Spark SQL, but the example given is too simple to determine the time semantics they support.
Using SQL directly as an API, however, has certain drawbacks:
- Insufficient time semantics, such as different window types for aggregations (e.g. tumbling / hopping / sessionization window) and point-in-time joins.
- Lack of composability. Feature pipelines can be complex. We need a language that allows building small pieces of logic independently and stitching them together, while making the pieces reusable.
Python interface
While SQL is increasingly gaining popularity with data scientists, Python is still the lingua franca of data science. In the last couple of years, both LinkedIn and Airbnb switched to a Python interface for their feature API.
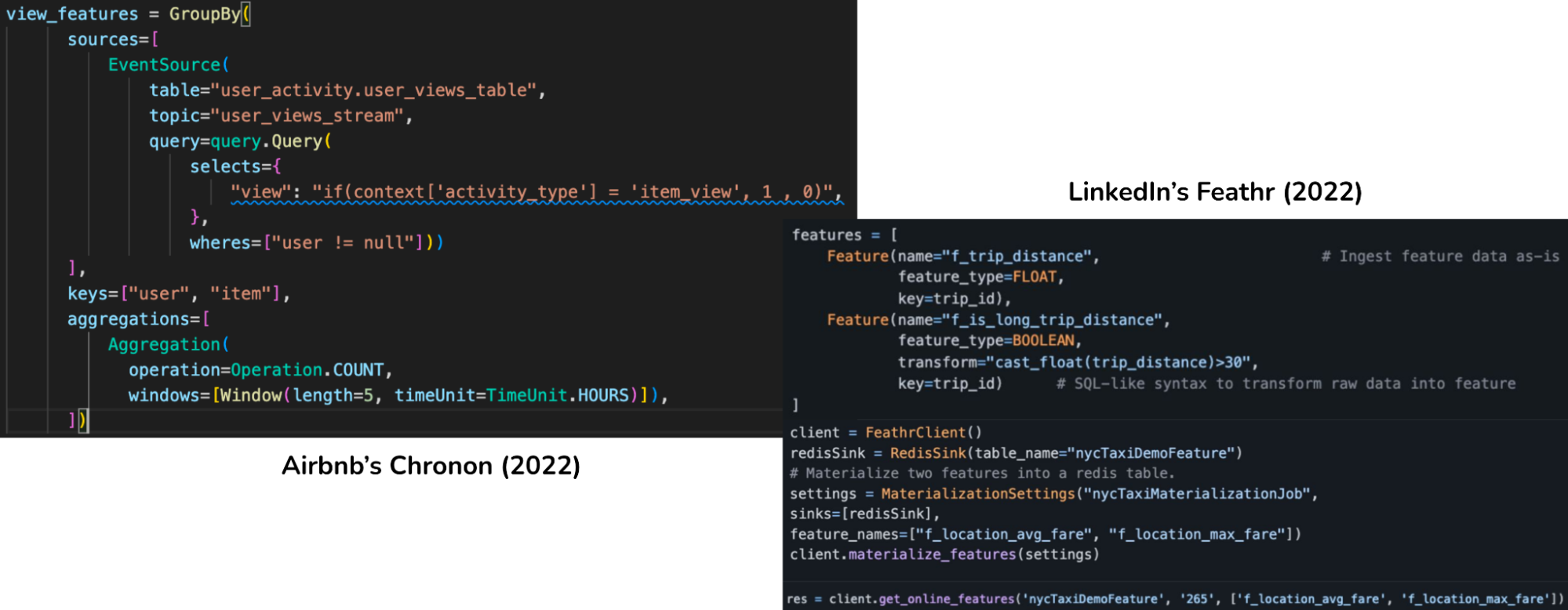
Note that while Feathr supports streaming processing, it does NOT support streaming aggregations.
Considerations for feature APIs
1. One-off batch computation vs. ongoing stream computation
If you compute your feature on fixed batch data like a CSV file, it’s a one-off job. If you compute your feature on an incoming stream of data, the value needs to be continually computed with new values, which makes it a long-running job. After you’ve written a streaming feature logic, executing this logic requires starting a long-running job. Data scientists, who are used to working with notebooks, might find executing and maintaining long-running jobs challenging.
Because the outputs of streaming feature computation are continually generated, we need to write them somewhere. Figuring out where to write to and configuring an output schema with the correctly-formatted keys to match existing data tables can also be challenging.
It’d be ideal if the feature API backend also handles starting streaming jobs and output schemas.
2. Design decision: separation of transformation logic and feature logic
Transformation refers to the function applied on data: e.g. count of product views, mean of transaction value. A feature consists of a transformation, sources (where to apply this transformation on), and sinks (where to write the computed feature values to). Transformation logic and feature logic don’t have to be written in the same language.
For both DoorDash and Snap, transformation logic is in SQL, but feature logic is configured in YAML. For Feathr and Airbnb, both transformation logic and feature logic are in Python.
The separation of transformation and feature serves two purposes: It allows the reuse of transformation logic. For example, the same transformation can be applied to different sources to create different features. It creates a clean abstraction that allows different personas to work together. For example, data scientists can focus on creating transformations, and if they need help configuring the long-running jobs to compute their streaming features, they can collaborate with data engineers on feature configuration.
2. Functionality for fast experimentation
In this section, we’ll discuss the functionalities that can significantly speed up iteration for streaming features.
Data discoverability and governance
- Feature discoverability: Say, you have a new idea for a streaming feature to be used for your model. Because feature computation and storage are expensive, the first thing you might want to do is to see whether that feature is already being used by another model or another team, so that you can reuse it
- Source discoverability: You might want to see if this feature is actually feasible given your data setup. You might want to look up what sources are available.
- Data governance: Talking about data discoverability, it’s important to consider that some data is sensitive and shouldn’t be accessible by everyone. It’s important to:
- Assign roles to users and configure which data should be accessible by which roles.
- Automate masking of sensitive, PII data.
- Propagate data policy – if a feature is derived from a sensitive column, it should also be marked as sensitive.
Automated backfills
Since you don’t know if this feature is helpful yet, you don’t want to deploy it to your feature store, say Redis, because it might incur high cost. You want to be able to experiment with it locally first. You want to train your model using this feature to see if it actually helps your model. Generating historical values for this streaming feature so that you can experiment with it is called backfilling. Backfilling for streaming features is hard, as it requires point-in-time correctness. For more information on time travel and backfilling, see Introduction to streaming for data scientists.
In a talk in December 2021, Spotify mentioned 3 killer features for fast iteration that they wish they had. The second point is automated backfills. [The two other points are point-in-time joins and streaming ingestion, which deserve their own blog post].
Comparison of feature platforms
| Feature store | Feature API (transformation - feature) |
Stream comput. engine | |
| Venice, Fedex | Python - Python | Samza, Flink | |
| Airbnb | HBase-based | Python - Python | Spark Streaming |
| Instacart | Scylla, Redis | ? - YAML | Flink |
| DoorDash | Redis, CockroachDB | SQL - YAML | Flink |
| Snap | KeyDB (multithreaded fork of Redis) | SQL - YAML | Spark Streaming |
| Stripe | In-house, Redis | Scala - ? | Spark Streaming |
| Meta (FB) | Scala-like - ? | XStream, Velox | |
| Spotify | Bigtable | Flink SQL - ? | Flink |
| Uber | Cassandra, DynamoDB | DSL - ? | Flink |
| Lyft | Redis, DynamoDB | SQL - YAML | Flink |
| In-house, memcached | R | Flink | |
| Criteo | Couchbase | SQL - JSON | Flink |
| Binance | Flink SQL - Python | Flink | |
| Manhattan, CockroachDB | Scala | Heron | |
| Gojek | DynamoDB | SQL - JSON | Flink |
| Etsy | Bigtable | Scala - ? | Dataflow |
Reference feature platforms
- [2018]
- Paypal: Data Pipelines for Real-Time Fraud Prevention at Scale (Mikhail Kourjanski)
- Airbnb: Zipline—Airbnb’s Declarative Feature Engineering Framework (Nikhil Simha and Varant Zanoyan)
- [2019]
- Stripe: Reproducible Machine Learning with Functional Programming (Oscar Boykin)
- Uber: Michelangelo Palette: A Feature Engineering Platform at Uber (Amit Nene)
- Pinterest: Big Data Machine Learning Platform at Pinterest (Yongsheng Wu)
- [2020]
- Meta: F3: Next-generation Feature Framework at Facebook (David Chung & Qiao Yang)
- “Facebook’s Feature Store” (Jun Wan, 2021)
- Criteo: Building FeatureFlow, Criteo’s feature data generation platform (Piyush Narang)
- Meta: F3: Next-generation Feature Framework at Facebook (David Chung & Qiao Yang)
- [2021]
- DoorDash: Building Riviera: A Declarative Real-Time Feature Engineering Framework (Allen Wang & Kunal Shah)
- Spotify: Jukebox : Spotify’s Feature Infrastructure (Aman Khan & Daniel Kristjansson)
- Pinterest: “Streamlining the Pinterest ML Feature Ecosystem” (Se Won Jang & Sihan Wang)
- [2022]
- LinkedIn: Open sourcing Feathr – LinkedIn’s feature store for productive machine learning (David Stein)
- DoorDash: Introducing Fabricator: A Declarative Feature Engineering Framework (Kunal Shah). Fabricator subsumes DoorDash’s previous declarative feature engineering framework Riviera.
- Snap: Speed Up Feature Engineering for Recommendation Systems
- Instacart:
- Coupang Eats: Eats data platform: Empowering businesses with data (Fred Fu, Coupang 2022)
- Airbnb: Chronon - Airbnb’s Feature Engineering Framework (Nikhil Simha). Zipline matured into Chronon, with improved APIs. Chronon is not yet open source.
- Binance:
- Gojek: Feature Engineering at Scale with Dagger and Feast (Ravi Suhag)
- Faire: Building Faire’s new marketplace ranking infrastructure (Sam Kenny)
Conclusion
Speed matters. A well-designed feature platform can improve both the speed at which fresh data can be used to improve ML predictions and the iteration speed for data scientists to improve ML models.
However, building a feature platform requires non-trivial investment. The companies that have discussed their feature platforms are reasonably large tech companies with plenty of expertise and resources. Even then, it can still take 10s of engineers multiple years to build.
When I asked the tech lead of one of these platforms why it took them so long to build their platform, he said: “A lot of time could’ve been saved if we knew what we were doing.” Building a feature platform is a trial and error process, and a wrong design decision could delay the project for a year.
As we gain more understanding of the requirements for feature platforms and the underlying technology for streaming computation matures, this process will become more straightforward. I’m excited to see more companies successfully adopt a feature platform without significant investment.
Acknowledgments
I’d like to thank Deepyaman Datta, Chloe He, Zhenzhong Xu, Astasia Myers, and Luke Metz for giving me feedback on the post. Thanks Nikhil Simha, Hangfei Lin, and many other who have generously answered many of my questions.
Appendix
Batch features vs. real-time features vs. near real-time features
See Real-time machine learning: challenges and solutions for more detail.
Batch features
Batch features are the easiest to set up, since companies can use their existing batch pipeline and only need to add:
- A key-value store low latency retrieval.
- A mechanism to automatically push the computed batch features to the key-value store.
Two main drawbacks of batch features:
- Feature staleness. If features are computed every hour, they are up to one hour stale.
- Wasted computation. A company told me they need to compute features for 3 million users each time, which takes them 6 hours, therefore they can refresh their features once every 6 hours. However, only 5% of these users visit their site a day, which means that 95% of the computation is actually wasted.
Real-time features
Real-time features are usually the next type to be deployed. Say, if you want to compute the number of views your product has had in the last 30 minutes in real-time, here are two of several simple ways you can do so:
- Create a lambda function that takes in all the recent user activities and counts the number of views.
- Store all the user activities in a database like postgres and write a SQL query to retrieve this count.
Because features are computed at prediction time, they are fresh, e.g. in the order of milliseconds.
While real-time features are easy to set up, they’re harder to scale. Because real-time features are computed upon receiving prediction requests, their computation latency adds directly to user-facing latency. Traffic growth and fluctuation can significantly affect computation latency. Complex features might be infeasible to support since they might take too long to compute.
Near RT / streaming features
Like batch features, near RT features are also precomputed and at prediction time, the latest values are retrieved and used. Since features are computed async, feature computation latency doesn’t add to user-facing latency. You can use as many features or as complex features as you want.
Unlike batch features, near RT feature values are recomputed much more frequently, so feature staleness can be in the order of seconds (it’s only “near” instead of “completely” real-time.) If a user doesn’t visit your site, its feature values won’t be recomputed, avoiding wasted computation. Near RT features are computed using a streaming processing engine.