What I learned from looking at 900 most popular open source AI tools
[Hacker News discussion, LinkedIn discussion, Twitter thread]
Update (Feb 2026): The full list of open source AI repos is hosted at Good AI List, updated daily. It’s balooned to 15K repos, and you can submit missing repos. You can also find some of them on my cool-llm-repos list on GitHub.
Four years ago, I did an analysis of the open source ML ecosystem. Since then, the landscape has changed, so I revisited the topic. This time, I focused exclusively on the stack around foundation models.
Data
I searched GitHub using the keywords gpt, llm, and generative ai. If AI feels so overwhelming right now, it’s because it is. There are 118K results for gpt alone.
To make my life easier, I limited my search to the repos with at least 500 stars. There were 590 results for llm, 531 for gpt, and 38 for generative ai. I also occasionally checked GitHub trending and social media for new repos.
After MANY hours, I found 896 repos. Of these, 51 are tutorials (e.g. dair-ai/Prompt-Engineering-Guide) and aggregated lists (e.g. f/awesome-chatgpt-prompts). While these tutorials and lists are helpful, I’m more interested in software. I still include them in the final list, but the analysis is done with the 845 software repositories.
It was a painful but rewarding process. It gave me a much better understanding of what people are working on, how incredibly collaborative the open source community is, and just how much China’s open source ecosystem diverges from the Western one.
The New AI Stack
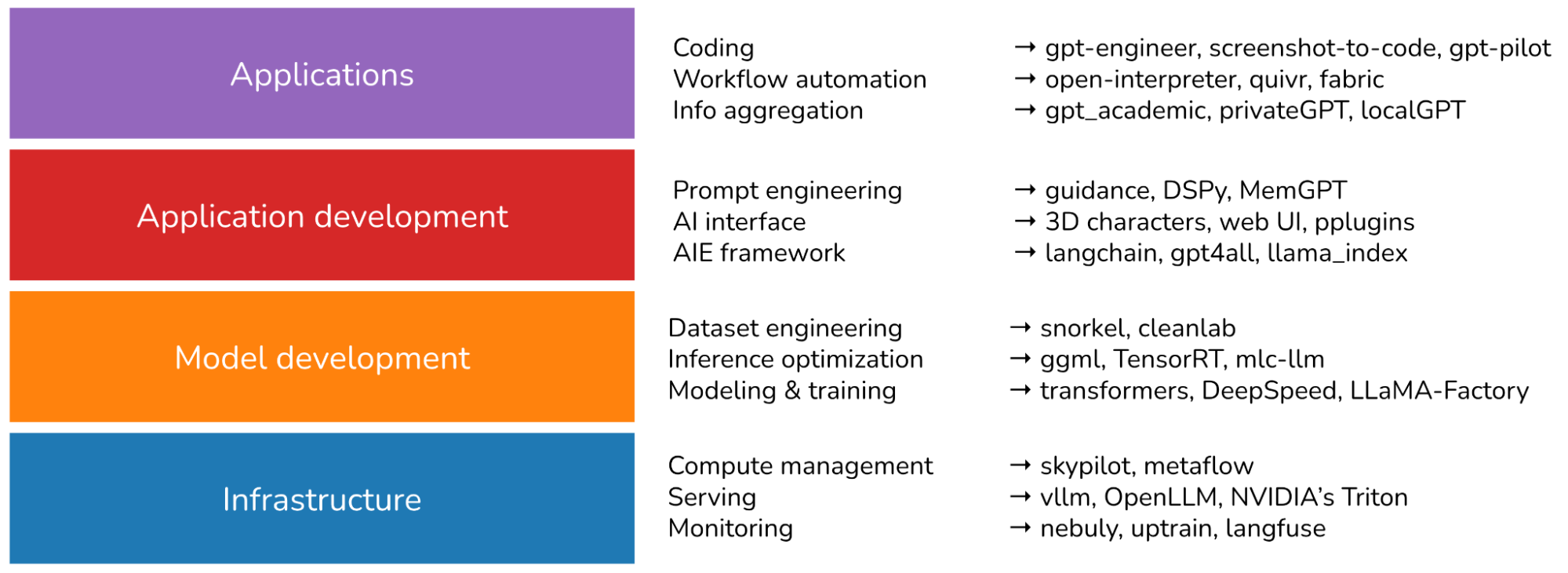
I think of the AI stack as consisting of 3 layers: infrastructure, model development, and application development.
-
Infrastructure
At the bottom is the stack is infrastructure, which includes toolings for serving (vllm, NVIDIA’s Triton), compute management (skypilot), vector search and database (faiss, milvus, qdrant, lancedb), ….
-
Model development
This layer provides toolings for developing models, including frameworks for modeling & training (transformers, pytorch, DeepSpeed), inference optimization (ggml, openai/triton), dataset engineering, evaluation, ….. Anything that involves changing a model’s weights happens in this layer, including finetuning.
-
Application development With readily available models, anyone can develop applications on top of them. This is the layer that has seen the most actions in the last 2 years and is still rapidly evolving. This layer is also known as AI engineering.
Application development involves prompt engineering, RAG, AI interface, …
Outside of these 3 layers, I also have two other categories:
- Model repos, which are created by companies and researchers to share the code associated with their models. Examples of repos in this category are
CompVis/stable-diffusion,openai/whisper, andfacebookresearch/llama. - Applications built on top of existing models. The most popular types of applications are coding, workflow automation, information aggregation, …
Note: In an older version of this post, Applications was included as another layer in the stack.
AI stack over time
I plotted the cumulative number of repos in each category month-over-month. There was an explosion of new toolings in 2023, after the introduction of Stable Diffusion and ChatGPT. The curve seems to flatten in September 2023 because of three potential reasons.
- I only include repos with at least 500 stars in my analysis, and it takes time for repos to gather these many stars.
- Most low-hanging fruits have been picked. What is left takes more effort to build, hence fewer people can build them.
- People have realized that it’s hard to be competitive in the generative AI space, so the excitement has calmed down. Anecdotally, in early 2023, all AI conversations I had with companies centered around gen AI, but the recent conversations are more grounded. Several even brought up scikit-learn. I’d like to revisit this in a few months to verify if it’s true.
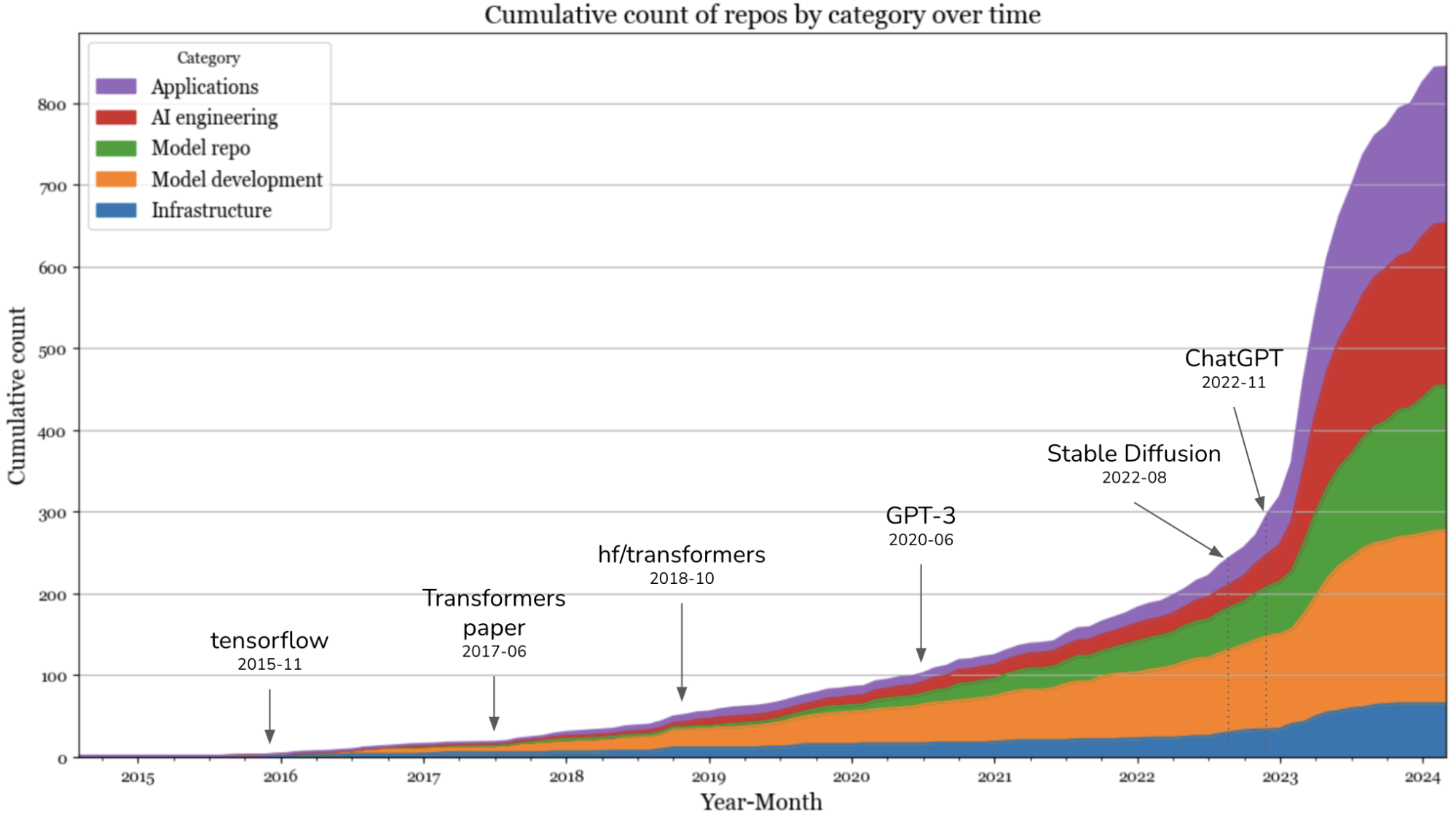
In 2023, the layers that saw the highest increases were the applications and application development layers. The infrastructure layer saw a little bit of growth, but it was far from the level of growth seen in other layers.
Applications
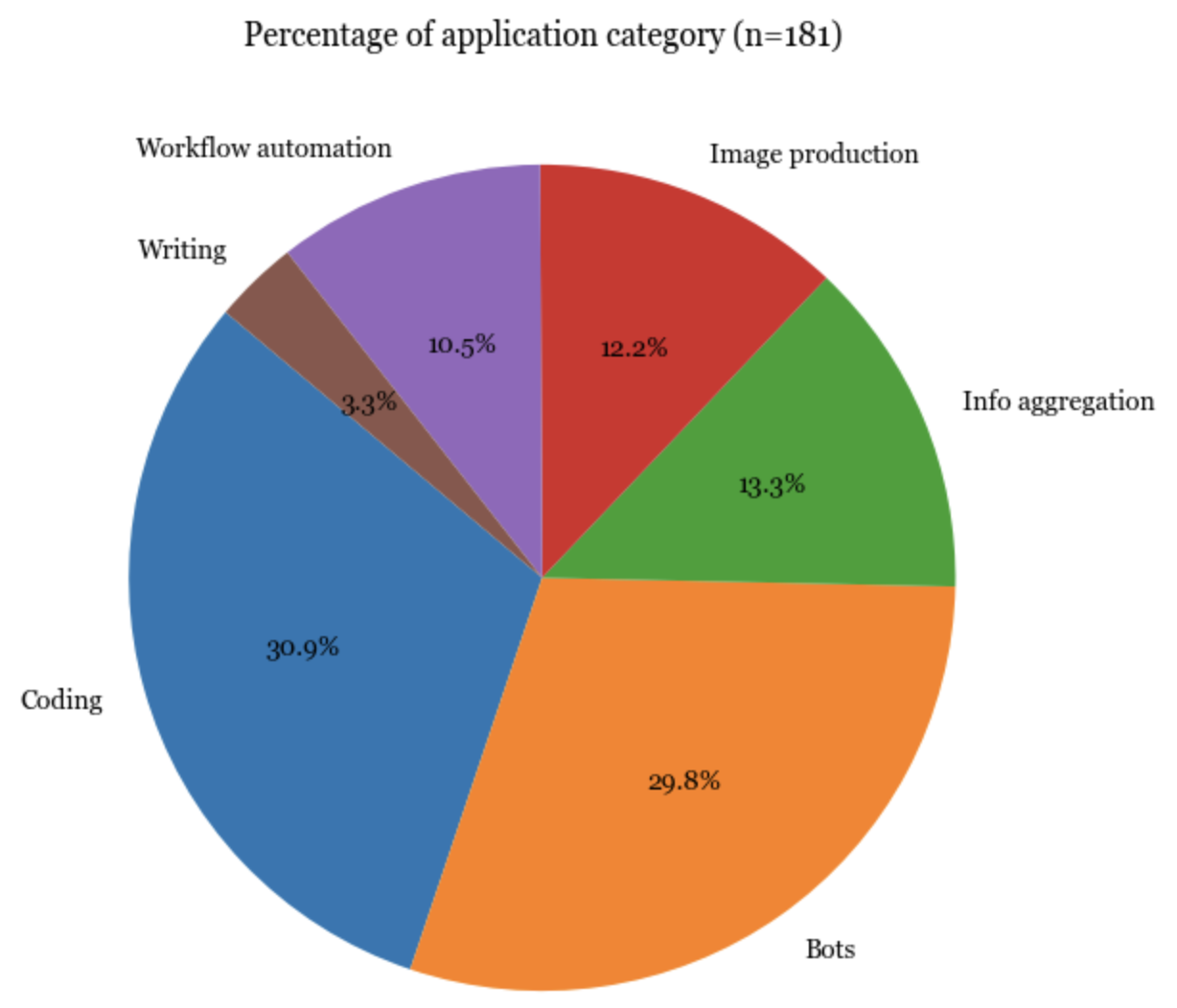
Not surprisingly, the most popular types of applications are coding, bots (e.g. role-playing, WhatsApp bots, Slack bots), and information aggregation (e.g. “let’s connect this to our Slack and ask it to summarize the messages each day”).
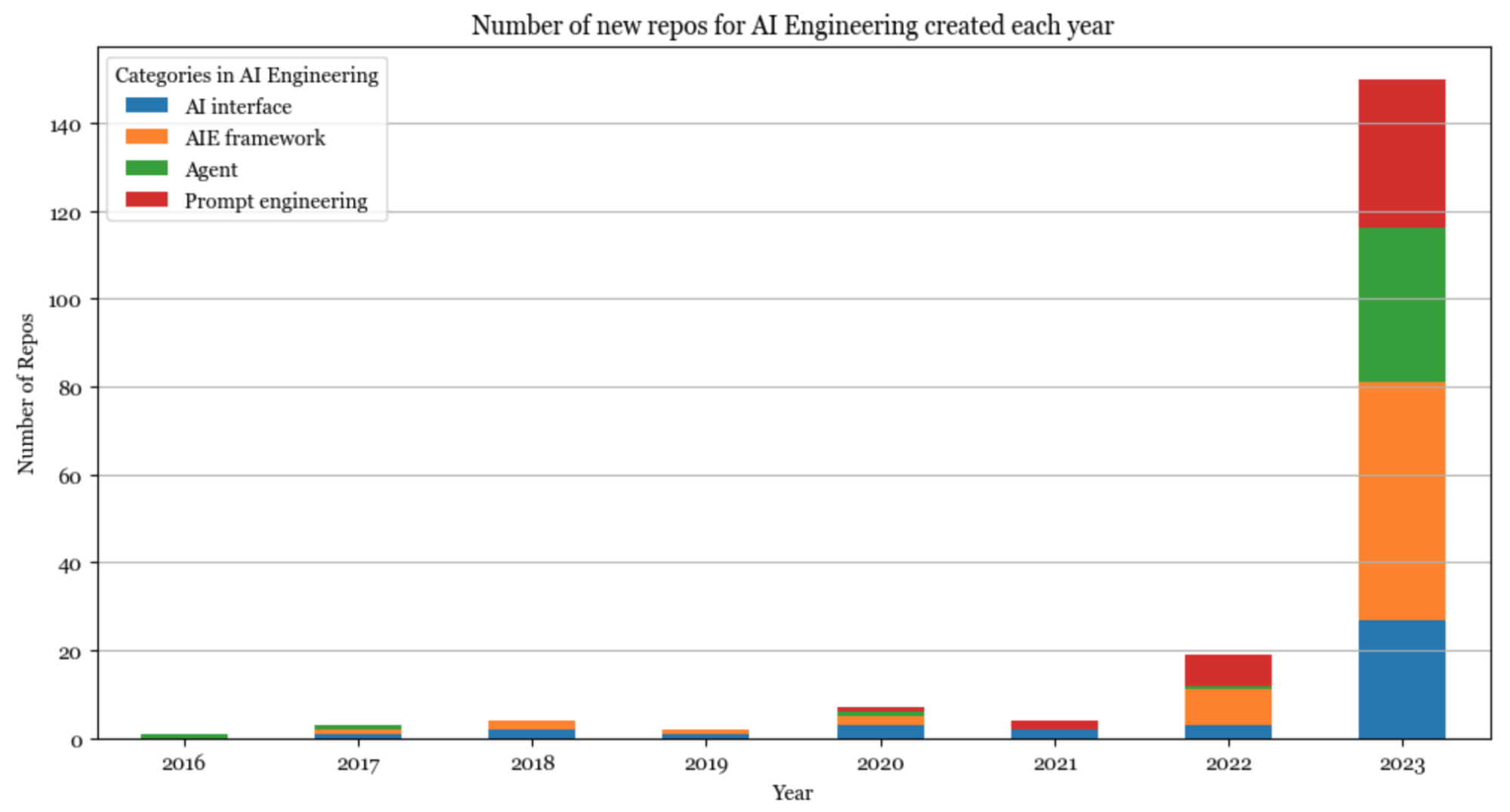
AI engineering
2023 was the year of AI engineering. Since many of them are similar, it’s hard to categorize the tools. I currently put them into the following categories: prompt engineering, AI interface, Agent, and AI engineering (AIE) framework.
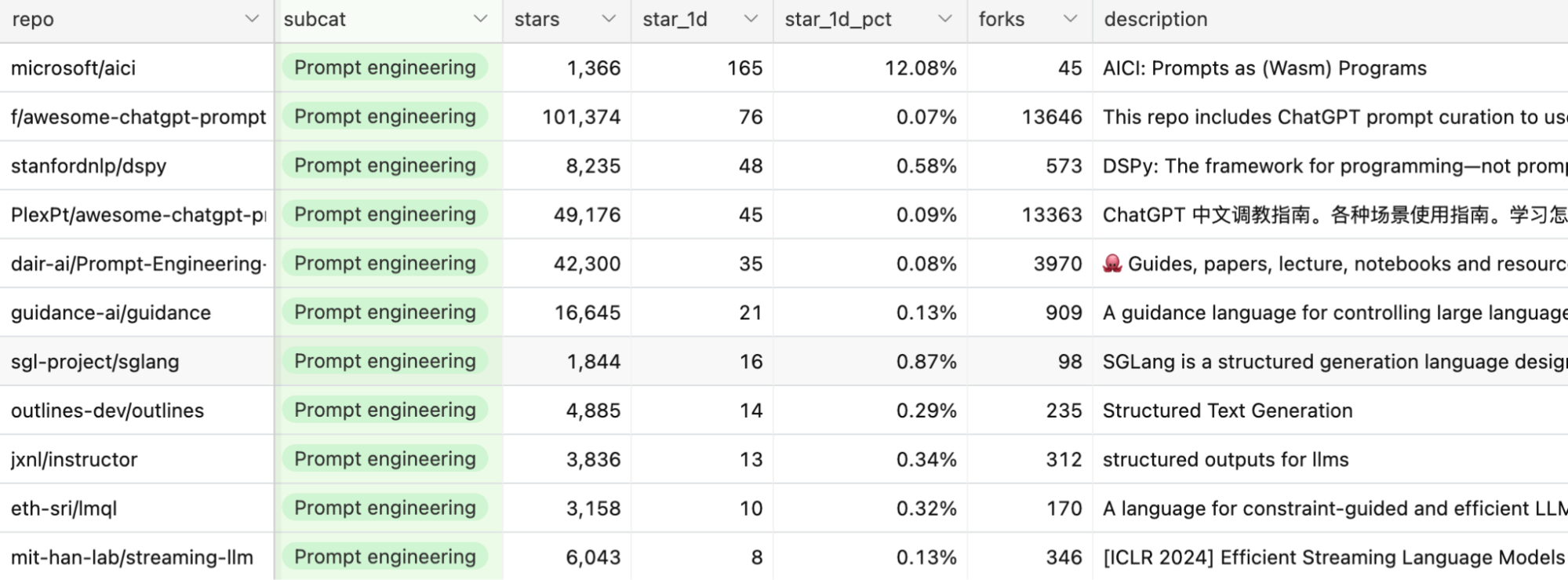
Prompt engineering goes way beyond fiddling with prompts to cover things like constrained sampling (structured outputs), long-term memory management, prompt testing & evaluation, etc.
AI interface provides an interface for your end users to interact with your AI application. This is the category I’m the most excited about. Some of the interfaces that are gaining popularity are:
- Web and desktop apps.
- Browser extensions that let users quickly query AI models while browsing.
- Bots via chat apps like Slack, Discord, WeChat, and WhatsApp.
- Plugins that let developers embed AI applications to applications like VSCode, Shopify, and Microsoft Offices. The plugin approach is common for AI applications that can use tools to complete complex tasks (agents).
AIE framework is a catch-all term for all platforms that help you develop AI applications. Many of them are built around RAG, but many also provide other toolings such as monitoring, evaluation, etc.
Agent is a weird category, as many agent toolings are just sophisticated prompt engineering with potentially constrained generation (e.g. the model can only output the predetermined action) and plugin integration (e.g. to let the agent use tools).
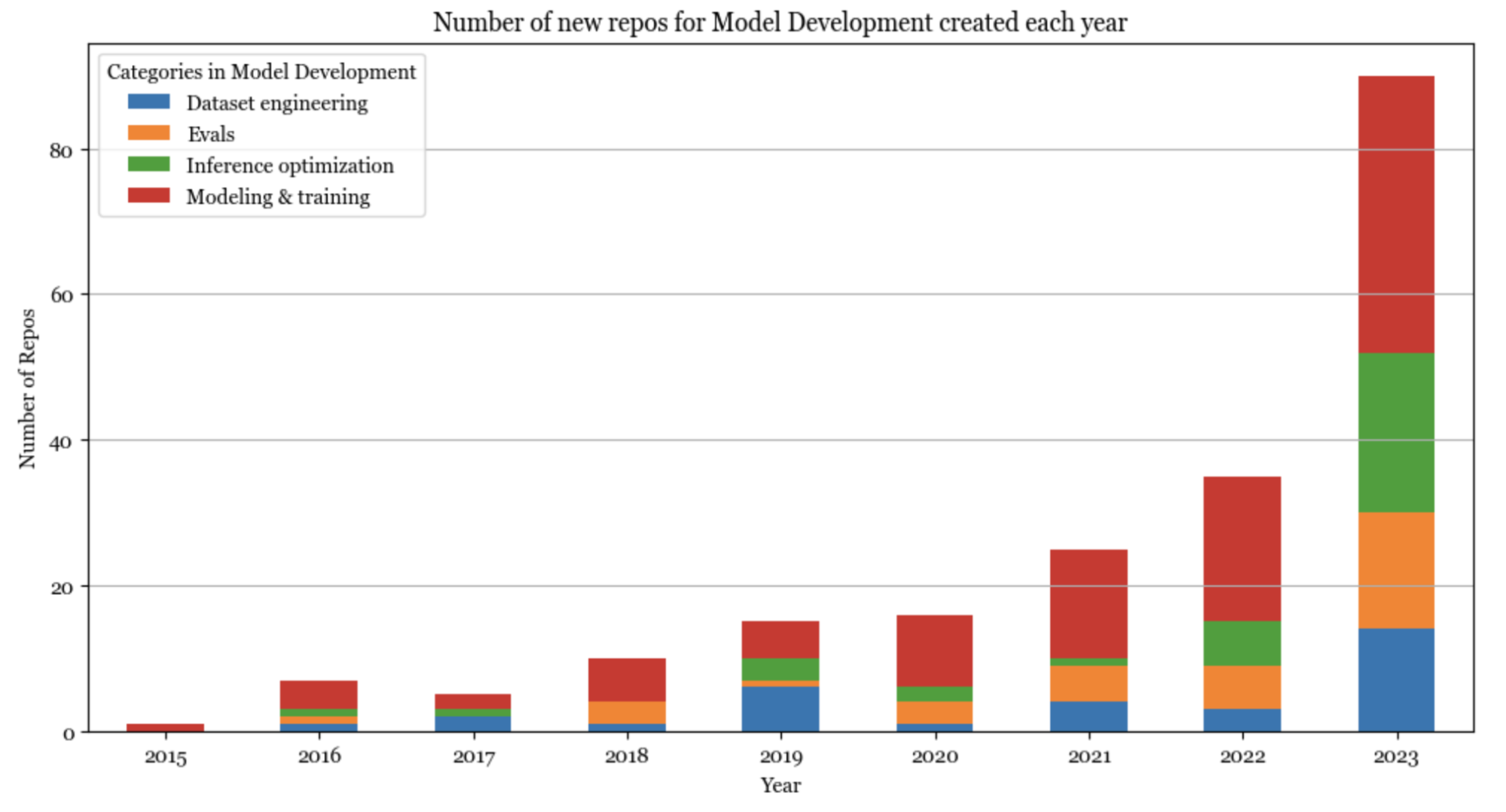
Model development
Pre-ChatGPT, the AI stack was dominated by model development. Model development’s biggest growth in 2023 came from increasing interest in inference optimization, evaluation, and parameter-efficient finetuning (which is grouped under Modeling & training).
Inference optimization has always been important, but the scale of foundation models today makes it crucial for latency and cost. The core approaches for optimization remain the same (quantization, low-ranked factorization, pruning, distillation), but many new techniques have been developed especially for the transformer architecture and the new generation of hardware. For example, in 2020, 16-bit quantization was considered state-of-the-art. Today, we’re seeing 2-bit quantization and even lower than 2-bit.
Similarly, evaluation has always been essential, but with many people today treating models as blackboxes, evaluation has become even more so. There are many new evaluation benchmarks and evaluation methods, such as comparative evaluation (see Chatbot Arena) and AI-as-a-judge.
Infrastructure
Infrastructure is about managing data, compute, and toolings for serving, monitoring, and other platform work. Despite all the changes that generative AI brought, the open source AI infrastructure layer remained more or less the same. This could also be because infrastructure products are typically not open sourced.
The newest category in this layer is vector database with companies like Qdrant, Pinecone, and LanceDB. However, many argue this shouldn’t be a category at all. Vector search has been around for a long time. Instead of building new databases just for vector search, existing database companies like DataStax and Redis are bringing vector search into where the data already is.
Open source AI developers
Open source software, like many things, follows the long tail distribution. A handful of accounts control a large portion of the repos.
One-person billion-dollar companies?
845 repos are hosted on 594 unique GitHub accounts. There are 20 accounts with at least 4 repos. These top 20 accounts host 195 of the repos, or 23% of all the repos on the list. These 195 repos have gained a total of 1,650,000 stars.
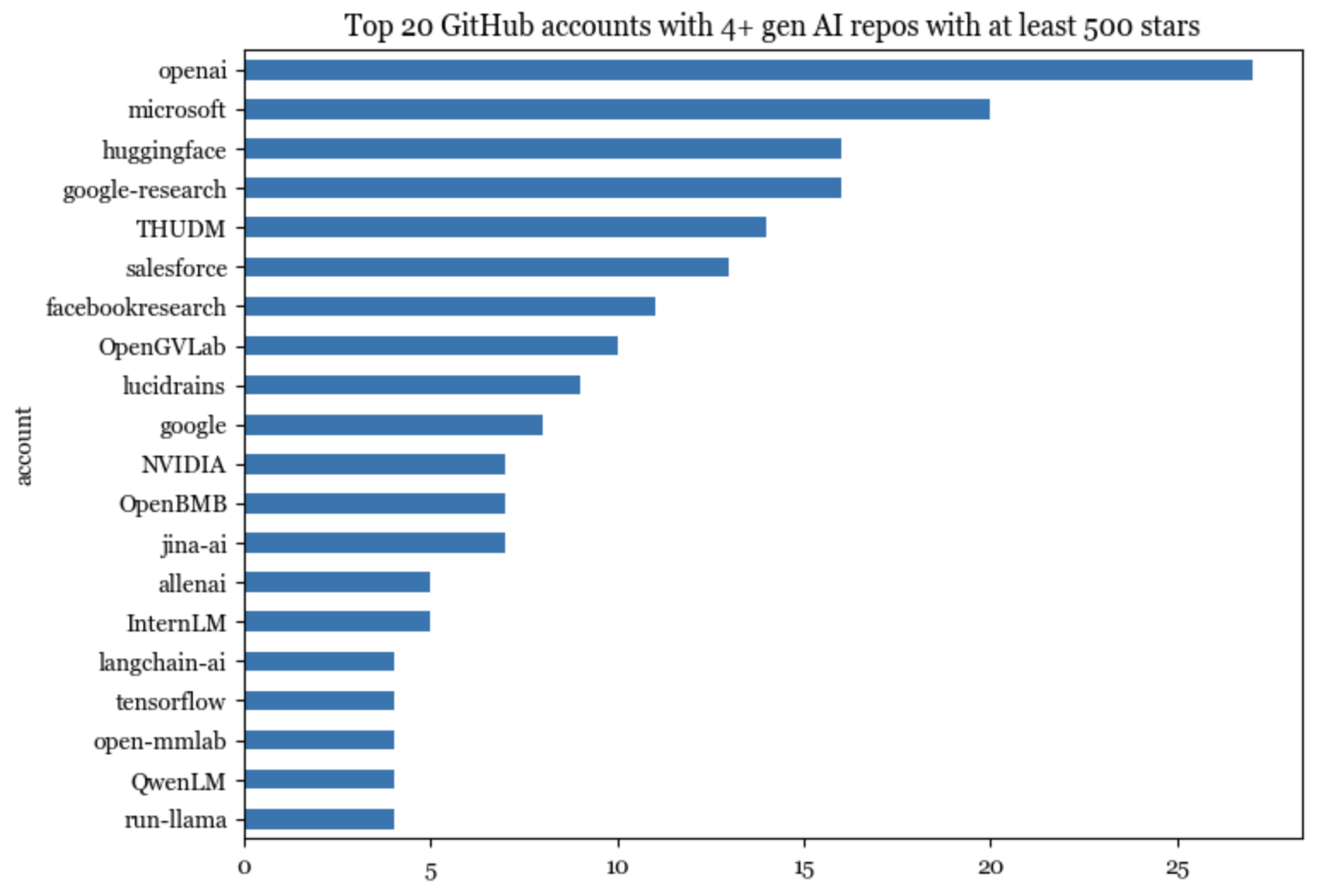
On Github, an account can be either an organization or an individual. 19/20 of the top accounts are organizations. Of those, 3 belong to Google: google-research, google, tensorflow.
The only individual account in these top 20 accounts is lucidrains. Among the top 20 accounts with the most number of stars (counting only gen AI repos), 4 are individual accounts:
- lucidrains (Phil Wang): who can implement state-of-the-art models insanely fast.
- ggerganov (Georgi Gerganov): an optimization god who comes from a physics background.
- Illyasviel (Lyumin Zhang): creator of Foocus and ControlNet who’s currently a Stanford PhD.
- xtekky: a full-stack developer who created gpt4free.
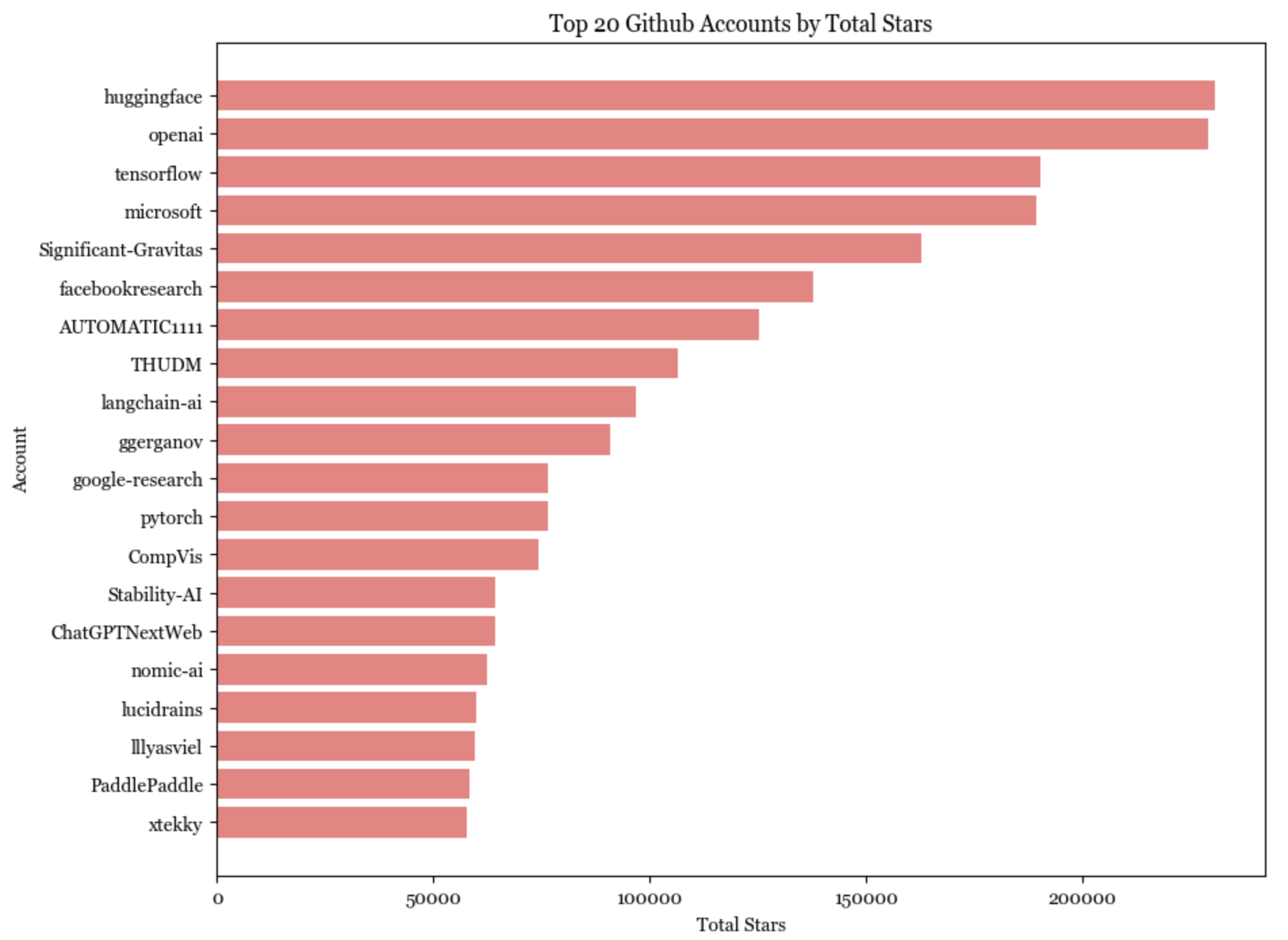
Unsurprisingly, the lower we go in the stack, the harder it is for individuals to build. Software in the infrastructure layer is the least likely to be started and hosted by individual accounts, whereas more than half of the applications are hosted by individuals.
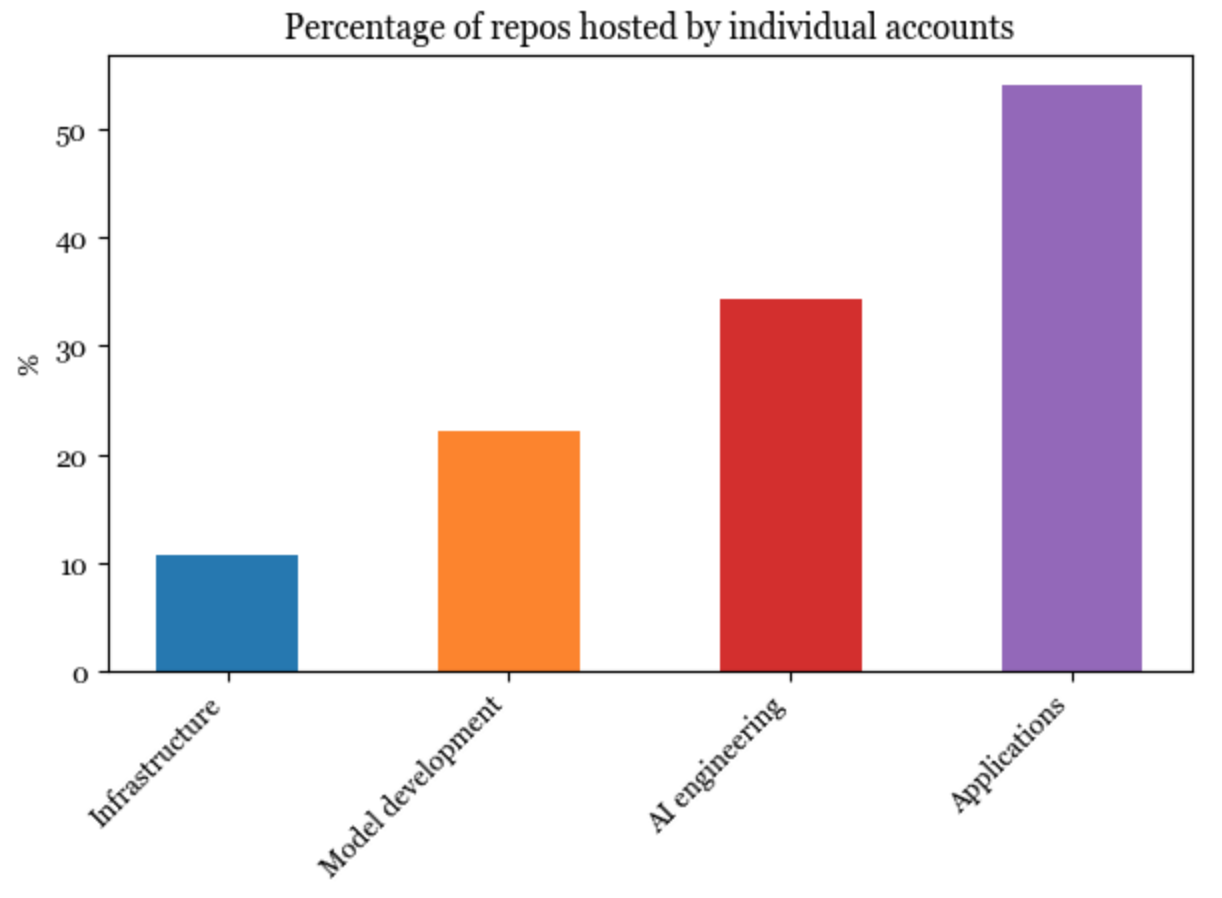
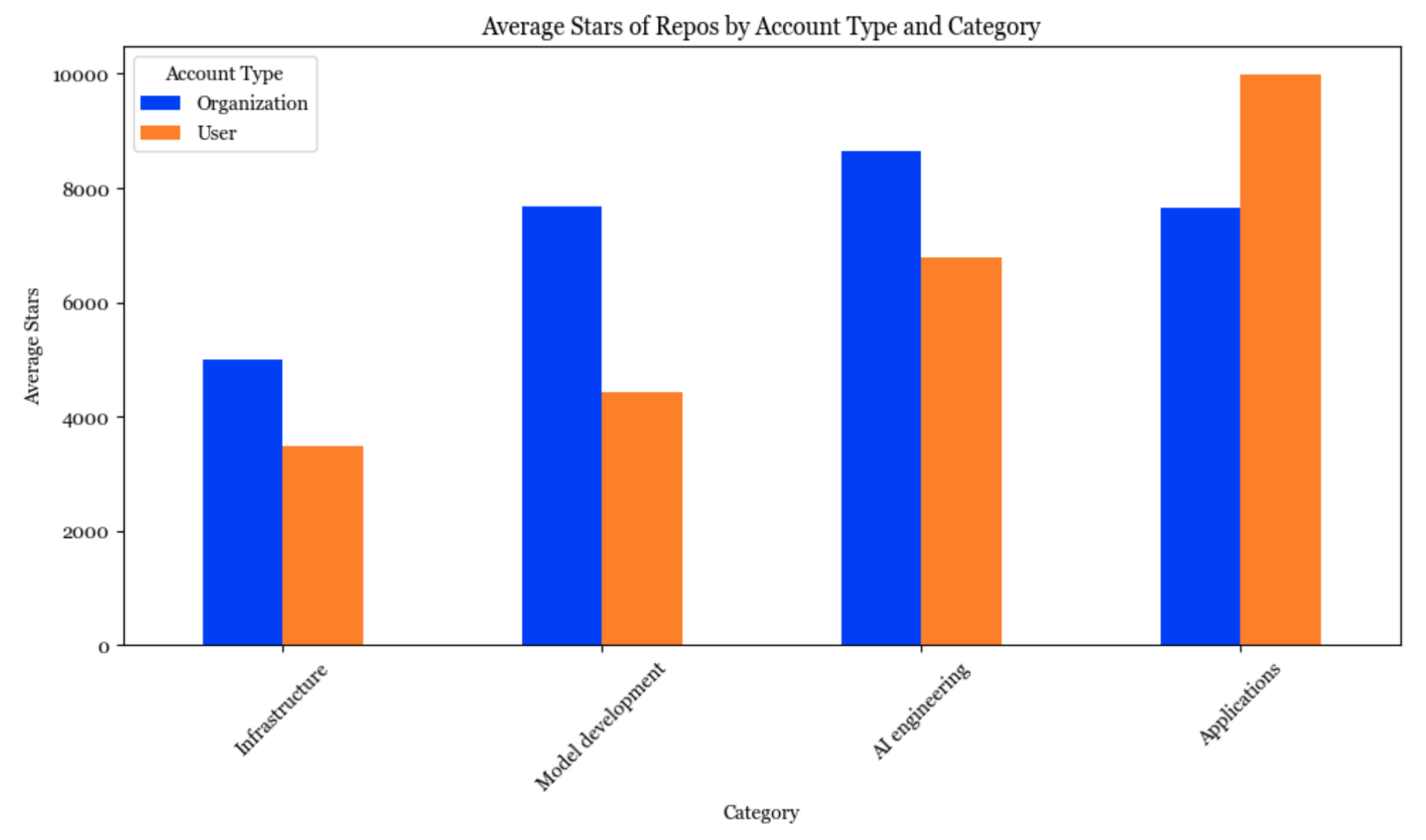
Applications started by individuals, on average, have gained more stars than applications started by organizations. Several people have speculated that we’ll see many very valuable one-person companies (see Sam Altman’s interview and Reddit discussion). I think they might be right.
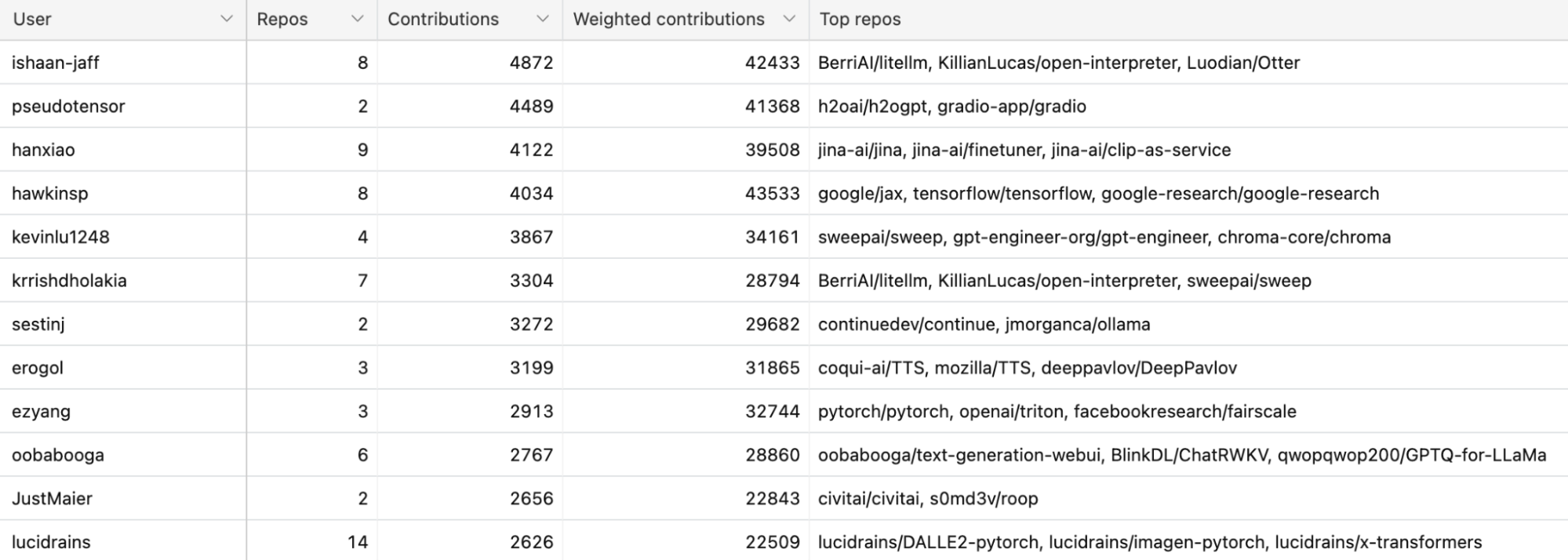
1 million commits
Over 20,000 developers have contributed to these 845 repos. In total, they’ve made almost a million contributions!
Among them, the 50 most active developers have made over 100,000 commits, averaging over 2,000 commits each. See the full list of the top 50 most active open source developers here.
The growing China's open source ecosystem
It’s been known for a long time that China’s AI ecosystem has diverged from the US (I also mentioned that in a 2020 blog post). At that time, I was under the impression that GitHub wasn’t widely used in China, and my view back then was perhaps colored by China’s 2013 ban on GitHub.
However, this impression is no longer true. There are many, many popular AI repos on GitHub targeting Chinese audiences, such that their descriptions are written in Chinese. There are repos for models developed for Chinese or Chinese + English, such as Qwen, ChatGLM3, Chinese-LLaMA.
While in the US, many research labs have moved away from the RNN architecture for language models, the RNN-based model family RWKV is still popular.
There are also AI engineering tools providing ways to integrate AI models into products popular in China like WeChat, QQ, DingTalk, etc. Many popular prompt engineering tools also have mirrors in Chinese.
Among the top 20 accounts on GitHub, 6 originated in China:
- THUDM: Knowledge Engineering Group (KEG) & Data Mining at Tsinghua University.
- OpenGVLab: General Vision team of Shanghai AI Laboratory
- OpenBMB: Open Lab for Big Model Base, founded by ModelBest & the NLP group at Tsinghua University.
- InternLM: from Shanghai AI Laboratory.
- OpenMMLab: from The Chinese University of Hong Kong.
- QwenLM: Alibaba’s AI lab, which publishes the Qwen model family.
Live fast, die young
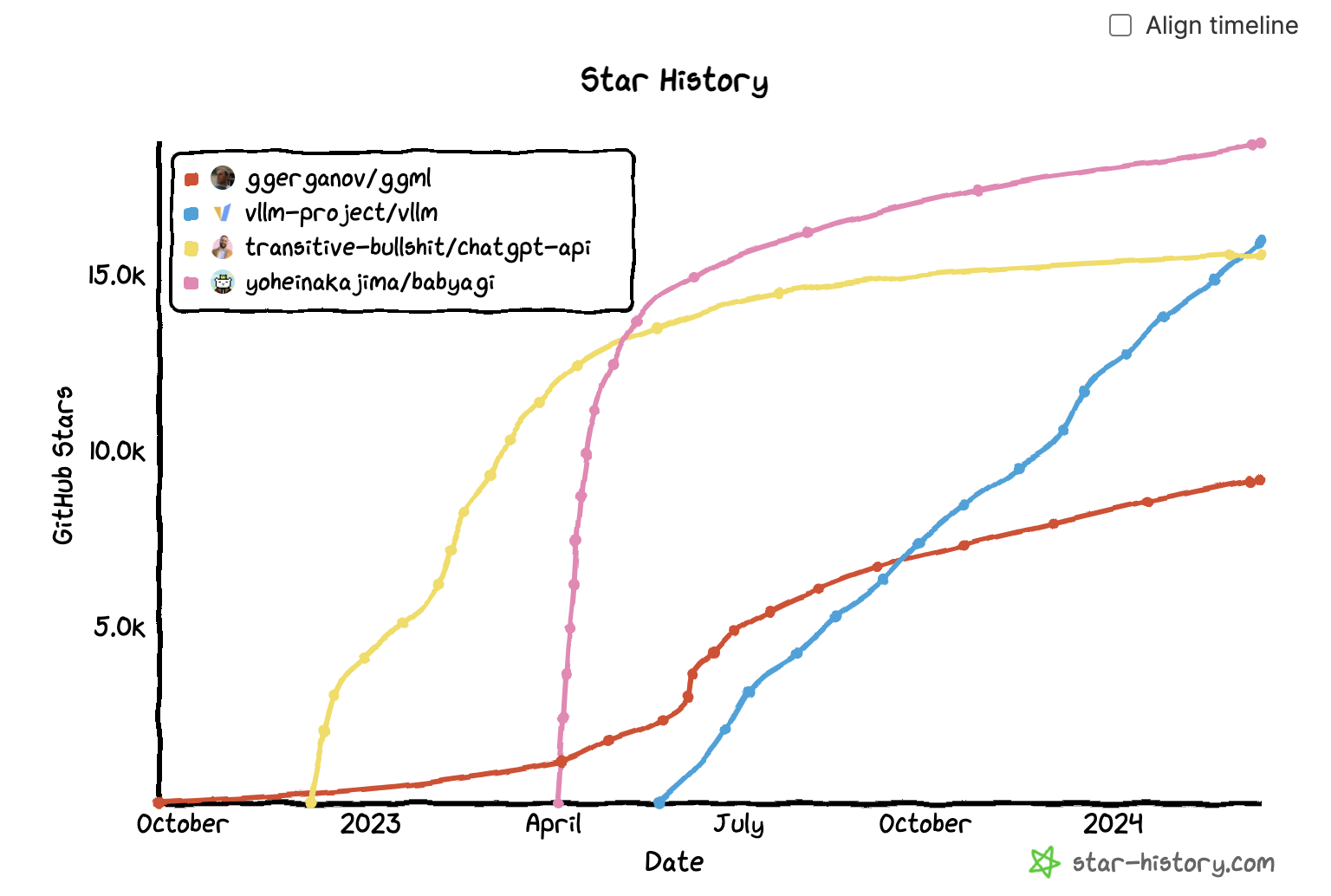
One pattern that I saw last year is that many repos quickly gained a massive amount of eyeballs, then quickly died down. Some of my friends call this the “hype curve”. Out of these 845 repos with at least 500 GitHub stars, 158 repos (18.8%) haven’t gained any new stars in the last 24 hours, and 37 repos (4.5%) haven’t gained any new stars in the last week.
Here are examples of the growth trajectory of two of such repos compared to the growth curve of two more sustained software. Even though these two examples shown here are no longer used, I think they were valuable in showing the community what was possible, and it was cool that the authors were able to get things out so fast.
My personal favorite ideas
So many cool ideas are being developed by the community. Here are some of my favorites.
- Batch inference optimization: FlexGen, llama.cpp
- Faster decoder with techniques such as Medusa, LookaheadDecoding
- Model merging: mergekit
- Constrained sampling: outlines, guidance, SGLang
- Seemingly niche tools that solve one problem really well, such as einops and safetensors.
Conclusion
Even though I included only 845 repos in my analysis, I went through several thousands of repos. I found this helpful for me to get a big-picture view of the seemingly overwhelming AI ecosystem. I hope the list is useful for you too. Please do let me know what repos I’m missing, and I’ll add them to the list!