Machine learning is going real-time
For a follow up of this post, see Real-time machine learning: challenges and solutions (2022).
After talking to machine learning and infrastructure engineers at major Internet companies across the US, Europe, and China, I noticed two groups of companies. One group has made significant investments (hundreds of millions of dollars) into infrastructure to allow real-time machine learning and has already seen returns on their investments. Another group still wonders if there’s value in real-time ML.
There seems to be little consensus on what real-time ML means, and there hasn’t been a lot of in-depth discussion on how it’s done in the industry. In this post, I want to share what I’ve learned after talking to about a dozen companies that are doing it.
Real-time machine learning is the approach of using real-time data to generate more accurate predictions and adapt models to changing environments. There are two levels of real-time machine learning that I’ll go over in this post.
- Level 1: Your ML system makes predictions in real-time (online predictions).
- Level 2: Your system can incorporate new data and update your model in real-time (continual learning).
I use “model” to refer to the machine learning model and “system” to refer to the infrastructure around it, including data pipeline and monitoring systems.
Table of contents
…. Level 1: Online predictions - your system can make predictions in real-time
…….. Use cases
………… Problems with batch predictions
…….. Solutions
………… Fast inference
………… Real-time pipeline
……………. Stream processing vs. batch processing
……………. Event-driven vs. request-driven
…….. Challenges
…. Level 2: Continual learning - your system can incorporate new data and update in real-time
…….. Defining “continual learning”
…….. Use case
…….. Solutions
…….. Challenges
………… Theoretical
………… Practical
…. The MLOps race between the US and China
…. Conclusion
[Level 1] Online predictions: your system can make predictions in real-time
Real-time here is defined to be in the order of milliseconds to seconds.
Use cases
Latency matters, especially for user-facing applications. In 2009, Google’s experiments demonstrated that increasing web search latency 100 to 400 ms reduces the daily number of searches per user by 0.2% to 0.6%. In 2019, Booking.com found that an increase of 30% in latency cost about 0.5% in conversion rates — “a relevant cost for our business.”
No matter how great your ML models are, if they take just milliseconds too long to make predictions, users are going to click on something else.
Problems with batch predictions
One non-solution is to avoid making predictions online. You can generate predictions in batch offline, store them (e.g. in SQL tables), and pull out pre-computed predictions when needed.
This can work when the input space is finite – you know exactly how many possible inputs to make predictions for. One example is when you need to generate movie recommendations for your users – you know exactly how many users there are. So you predict a set of recommendations for each user periodically, such as every few hours.
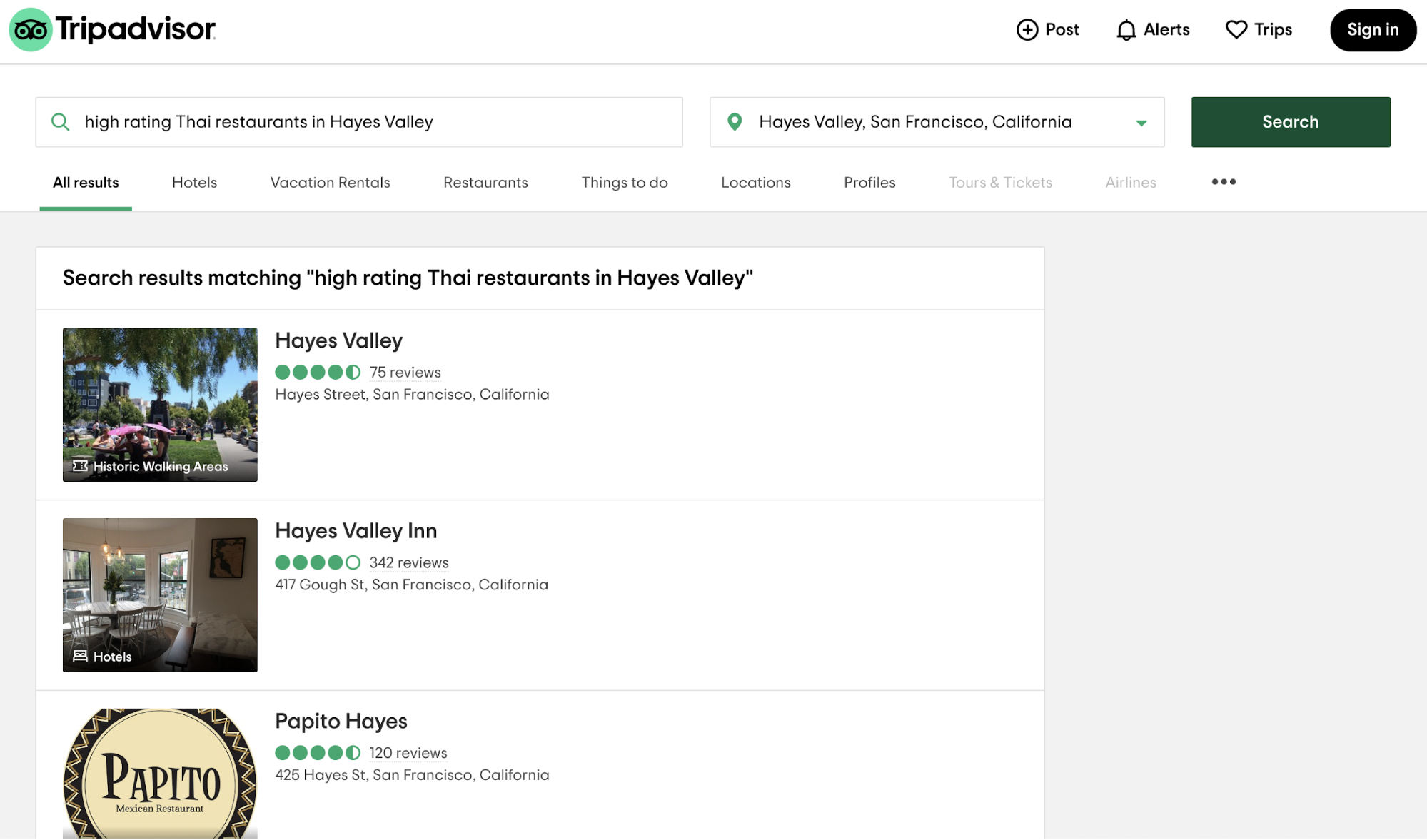
To make their user input space finite, many apps make their users choose from categories instead of entering wild queries. For example, if you go to TripAdvisor, you first have to pick a predefined metropolis area instead of being able to enter just any location.
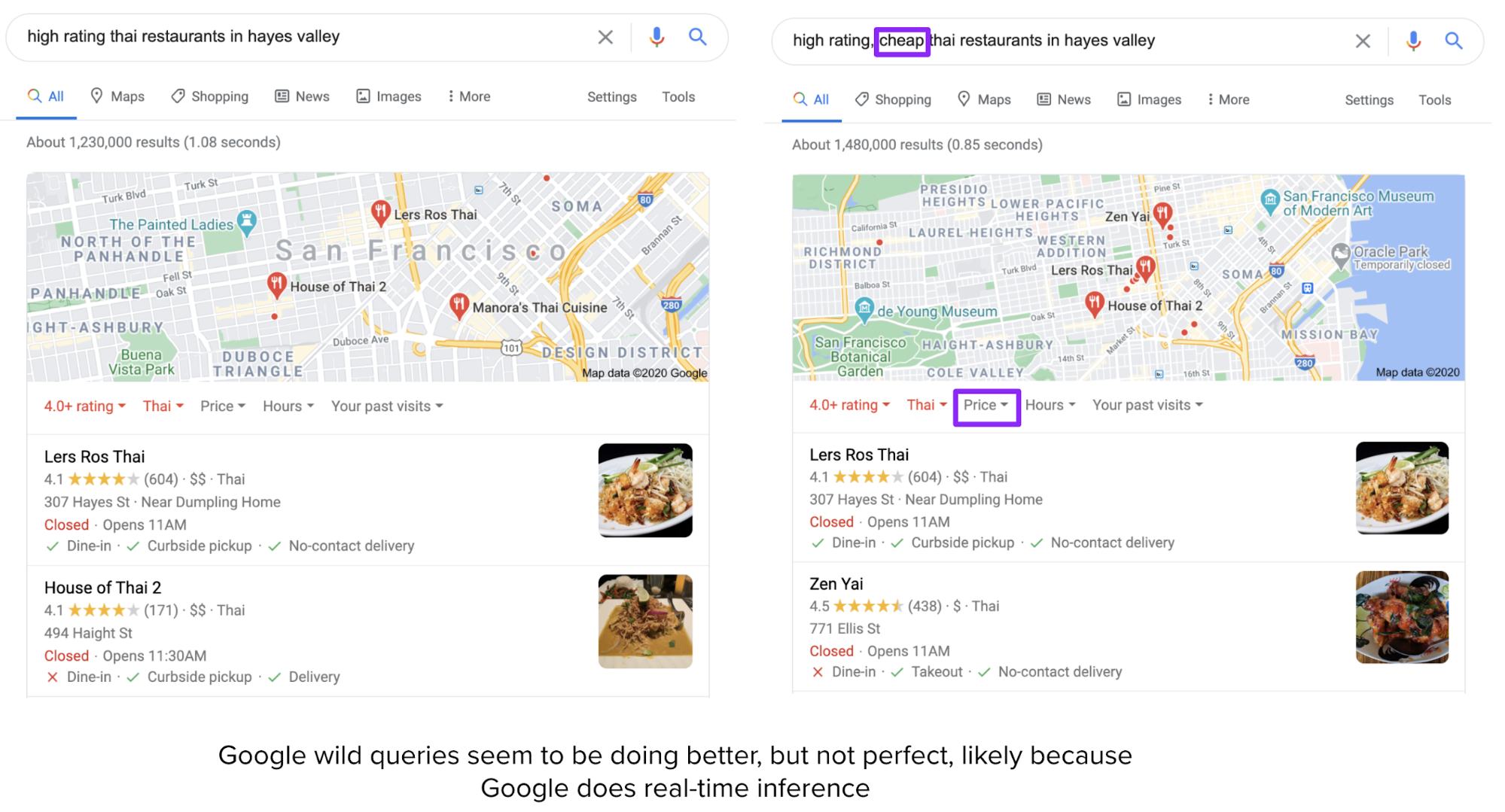
This approach has many limitations. TripAdvisor results are okay within their predefined categories, such as “Restaurants” in “San Francisco”, but are pretty bad when you try to enter wild queries like “high rating Thai restaurants in Hayes Valley”.
Limitations caused by batch predictions exist even in more technologically progressive companies like Netflix. Say, you’ve been watching a lot of horrors lately, so when you first log into Netflix, horror movies dominate recommendations. But you’re feeling bright today so you search “comedy” and start browsing the comedy category. Netflix should learn and show you more comedy in your list of their recommendations, right? But it can’t update the list until the next time batch recommendations are generated.
In the two examples above, batch predictions lead to decreases in user experience (which is tightly coupled with user engagement/retention), not catastrophic failures. Other examples are ad ranking, Twitter’s trending hashtag ranking, Facebook’s newsfeed ranking, estimating time of arrival, etc.
There are also many applications that, without online predictions, would lead to catastrophic failures or just wouldn’t work. Examples include high frequency trading, autonomous vehicles, voice assistants, unlocking your phones using face/fingerprints, fall detection for elderly care, fraud detection, etc. Being able to detect a fraudulent transaction that happened 3 hours ago is still better than not detecting it at all, but being able to detect it in real-time can prevent it from going through.
Switching from batch predictions to real-time predictions allows you to use dynamic features to make more relevant predictions. Static features are information that changes slowly or rarely – age, gender, job, neighborhood, etc. Dynamic features are features based on what’s happening right now – what you’re watching, what you’ve just liked, etc. Knowing a user’s interests right now will allow your systems to make recommendations much more relevant to them.
Solutions
For your system to be able to make online predictions, it has to have two components:
- Fast inference: model that can make predictions in the order of milliseconds
- Real-time pipeline: a pipeline that can process data, input it into model, and return a prediction in real-time
Fast inference
When a model is too big and taking too long to make predictions, there are three approaches:
1. Make models faster (inference optimization)
E.g. fusing operations, distributing computations, memory footprint optimization, writing high performance kernels targeting specific hardwares, etc.
2. Make models smaller (model compression)
Originally, this family of technique is to make models smaller to make them fit on edge devices. Making models smaller often makes them run faster. The most common, general technique for model compression is quantization, e.g. using 16-bit floats (half precision) or 8-bit integers (fixed-point) instead of 32-bit floats (full precision) to represent your model weights. In the extreme case, some have attempted 1-bit representation (binary weight neural networks), e.g. BinaryConnect and Xnor-Net. The authors of Xnor-Net spun off Xnor.ai, a startup focused on model compression which was acquired by Apple for a reported $200M.
Another popular technique is knowledge distillation – a small model (student) is trained to mimic a larger model or an ensemble of models (teacher). Even though the student is often trained with a pre-trained teacher, both may also be trained at the same time. One example of a distilled network used in production is DistilBERT, which reduces the size of a BERT model by 40%, while retaining 97% of its language understanding capabilities and being 60% faster.
Other techniques include pruning (finding parameters least useful to predictions and setting them to 0) and low-rank factorization (replacing the over-parametric convolution filters with compact blocks to both reduce the number of parameters and increase speed). See A Survey of Model Compression and Acceleration for Deep Neural Networks (Cheng et al.. 2017) for a detailed analysis.
The number of research papers on model compression is growing. Off-the-shelf utilities are proliferating. Awesome Open Source has a list of The Top 121 Model Compression Open Source Projects.
3. Make hardware faster
This is another research area that is booming. Big companies and startups alike are in a race to develop hardware that allows large ML models to do inference, even training, faster both on the cloud and especially on devices. IDC forecasts that by 2020, the combination of edge and mobile devices doing inferencing will total 3.7 billion units, with a further 116 million units doing training.
Real-time pipeline
Suppose you have a ride sharing app and want to detect fraudulent transactions e.g. payments using stolen credit cards. When the true credit owner discovers unauthorized payments, they’ll dispute with their bank and you’ll have to refund the charges. To maximize profits, fraudsters might call multiple rides either in succession or from multiple accounts. In 2019, merchants estimate fraudulent transactions account for an average of 27% of their annual online sales. The longer it takes for you to detect the stolen credit card, the more money you’ll lose.
To detect whether a transaction is fraudulent, looking at that transaction alone isn’t enough. You need to at least look into the recent history of the user involved in that transaction, their recent trips and activities in-app, the credit card’s recent transactions, and other transactions happening around the same time.
To quickly access these types of information, you want to keep as much of them in-memory as possible. Every time an event you care about happens – a user choosing a location, booking a trip, contacting a driver, canceling a trip, adding a credit card, removing a credit card, etc. – information about that event goes into your in-memory storage. It stays there for as long as they are useful (usually in order of days) then either goes into permanent storage (e.g. S3) or is discarded. The most common tool for this is Apache Kafka, with alternatives such as Amazon Kinesis. Kafka is a stream storage: it stores data as it streams.
Streaming data is different from static data – data that already exists somewhere in its entirety, such as CSV files. When reading from CSV files, you know when the job is finished. Streams of data never finish.
Once you’ve had a way to manage streaming data, you want to extract features to input into your ML models. On top of features from streaming data, you might also need features from static data (when was this account created, what’s the user’s rating, etc.). You need a tool that allows you to process streaming data as well as static data and join them together from various data sources.
Stream processing vs. batch processing
People generally use “batch processing” to refer to static data processing because you can process them in batches. This is opposed to “stream processing”, which processes each event as it arrives. Batch processing is efficient – you can leverage tools like MapReduce to process large amounts of data. Stream processing is fast because you can process each piece of data as soon as it comes. Robert Metzger, a PMC member at Apache Flink, disputed that streaming processing can be as efficient as batch processing because batch is a special case of streaming.
Processing stream data is more difficult because the data amount is unbounded and the data comes in at variable rates and speeds. It’s easier to make a stream processor do batch processing than making a batch processor do stream processing.
Apache Kafka has some capacity for stream processing and some companies use this capacity on top of their Kafka stream storage, but Kafka stream processing is limited in its ability to deal with various data sources. There have been efforts to extend SQL, the popular query language intended for static data tables, to handle data streams [1, 2]. However, the most popular tool for stream processing is Apache Flink, with native support for batch processing.
In the early days of machine learning production, many companies built their ML systems on top of their existing MapReduce/Spark/Hadoop data pipeline. When these companies want to do real-time inference, they need to build a separate pipeline for streaming data.
Having two different pipelines to process your data is a common cause for bugs in ML production, e.g. the changes in one pipeline aren’t correctly replicated in the other leading to two pipelines extracting two different sets of features. This is especially common if the two pipelines are maintained by two different teams, e.g. the development team maintains the batch pipeline for training while the deployment team maintains the stream pipeline for inference. Companies including Uber and Weibo have made major infrastructure overhaul to unify their batch and stream processing pipelines with Flink.
Event-driven vs. request-driven
The software world has gone microservices in the last decade. The idea is to break your business logic into small components – each component is a self-contained service – that can be maintained independently. The owner of each component can update to and test that component quickly without having to consult the rest of the system.
Microservices often go hand-in-hand with REST, a set of methods that let these microservices communicate. REST APIs are request-driven. A client (service) sends requests to tell its server exactly what to do via methods such as POST and GET, and its server responds with the results. A server has to listen to the request for the request to register.
Because in a request-driven world, data is handled via requests to different services, no one has an overview of how data flows through the entire system. Consider a simple system with 3 services:
- A manages drivers availability
- B manages ride demand
- C predicts the best possible price to show customers each time they request a ride
Because prices depend on availability and demands, service C’s output depends on the outputs from service A and B. First, this system requires inter-service communication: C needs to ping A and B for predictions, A needs to ping B to know whether to mobilize more drivers and ping C to know what price incentive to give them. Second, there’d be no easy way to monitor how changes in A or B logics affect the performance of service C, or to map the data flow to debug if service C’s performance suddenly goes down.
With only 3 services, things are already getting complicated. Imagine having hundreds, if not thousands of services like what major Internet companies have. Inter-service communication would blow up. Sending data as JSON blobs over HTTP – the way REST requests are commonly done – is also slow. Inter-service data transfer can become a bottleneck, slowing down the entire system.
Instead of having 20 services ping service A for data, what if whenever an event happens within service A, this event is broadcasted to a stream, and whichever service wants data from A can subscribe to that stream and pick out what it needs? What if there’s a stream all services can broadcast their events and subscribe to? This model is called pub/sub: publish & subscribe. This is what solutions like Kafka allow you to do. Since all data flows through a stream, you can set up a dashboard to monitor your data and its transformation across your system. Because it’s based on events broadcasted by services, this architecture is event-driven.
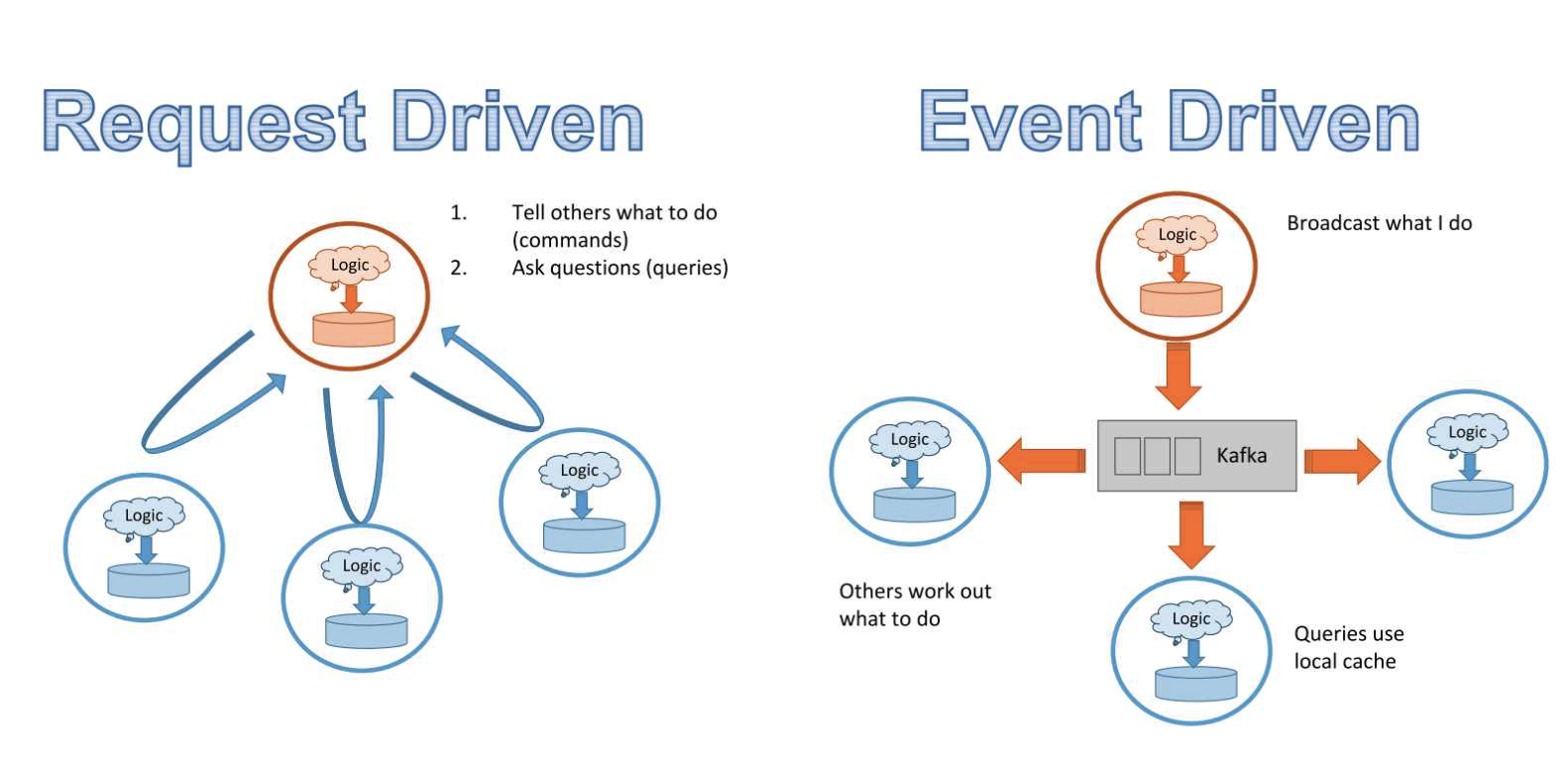
Request-driven architecture works well for systems that rely more on logics than on data. Event-driven architecture works better for systems that are data-heavy.
Challenges
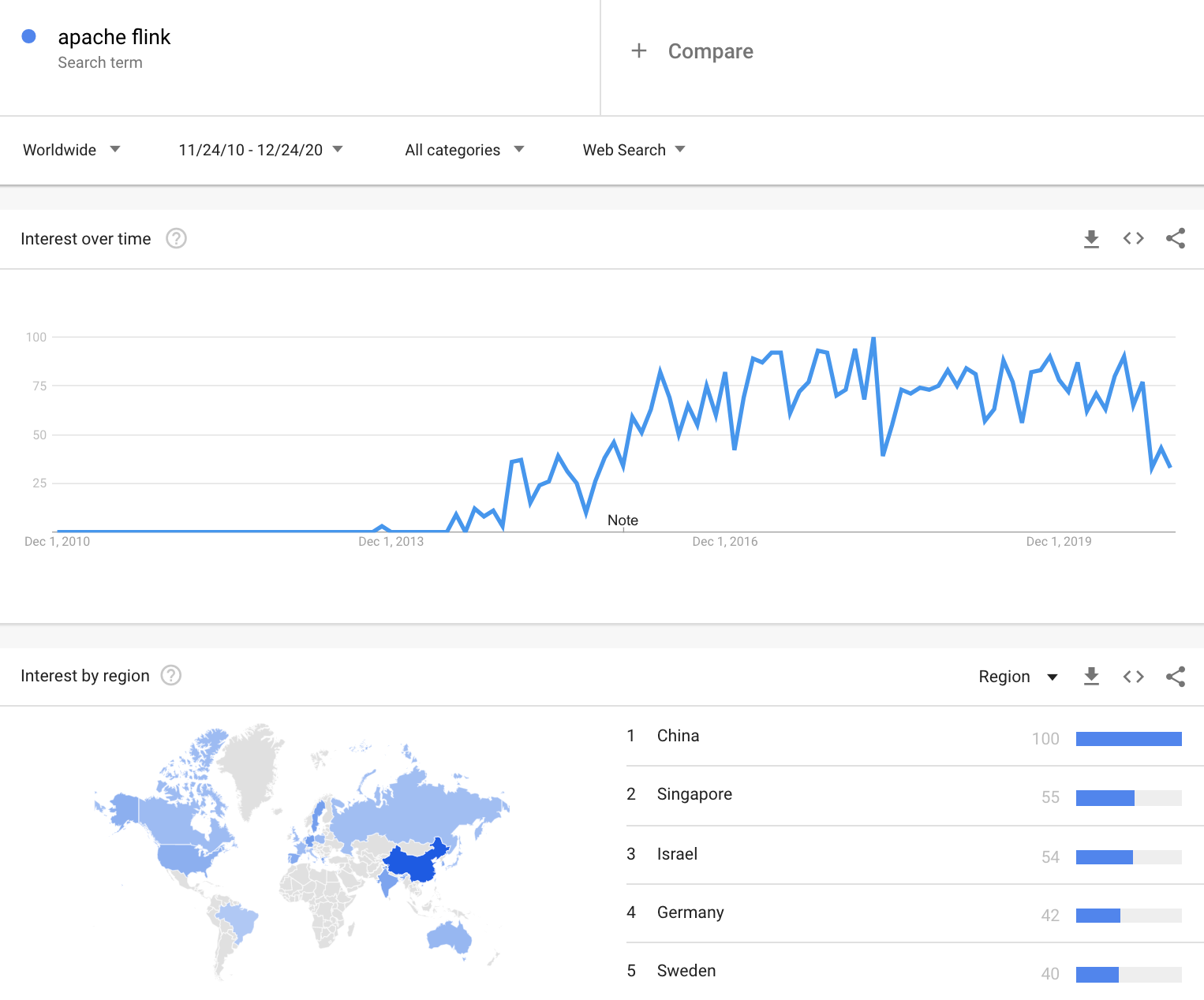
Many companies are switching from batch processing to stream processing, from request-driven architecture to event-driven architecture. My impression from talking to major Internet companies in the US and China is that this change is still slow in the US, but much faster in China. The adoption of streaming architecture is tied to the popularity of Kafka and Flink. Robert Metzger told me that he observed more machine learning workloads with Flink in Asia than in the US. Google Trends for “Apache Flink” is consistent with this observation.
There are many reasons why streaming isn’t more popular.
- Companies don’t see the benefits of streaming
- Their system isn’t at a scale where inter-service communication is a bottleneck.
- They don’t have applications that benefit from online predictions.
- They have applications that might benefit from online predictions but they don’t know that yet because they have never done online predictions before.
- High initial investment on infrastructure
Infrastructure updates are expensive and can jeopardize existing applications. Managers might not be willing to invest to upgrade their infra to allow online predictions. - Mental shift
Switching from batch processing to stream processing requires a mental shift. With batch processing, you know when a job is done. With stream processing, it’s never done. You can make rules such as get the average of all data points in the last 2 minutes, but what if an event that happened 2 minutes ago got delayed and hasn’t entered the stream yet? With batch processing, you can have well-defined tables and join them, but in streaming, there are no tables to join, then what does it mean to do a join operation on two streams? - Python incompatibility
Python is the lingua franca of machine learning whereas Kafka and Flink run on Java and Scala. Introducing streaming might create language incompatibility in the workflows. Apache Beam provides a Python interface on top of Flink for communicating with streams, but you’d still need people who can work with Java/Scala. - Higher processing cost
Batch processing means you can use your computing resources more efficiently. If your hardware is capable of processing 1000 data points at a time, it’s wasteful to use it to process only 1 data point at a time.
[Level 2] Continual learning: your system can incorporate new data and update in real-time
Real-time here is defined to be in the order of minutes
Defining "continual learning"
I used “continual learning” instead of “online training” or “online learning” because the two latter terms make people think about learning from each incoming data point. Very, very few companies actually do this because:
- This method suffers from catastrophic forgetting – neural networks abruptly forget previously learned information upon learning new information.
- It can be more expensive to run a learning step on only one data point than on a batch (this can be mitigated by having hardware just powerful enough to process exactly one data point).
Even if a model is learning with each incoming data point, it doesn’t mean the new weights are deployed after each data point. With our current limited understanding of how ML algorithms learn, the updated model needs to be evaluated first to see how well it does.
For most companies that do so-called online training or online learning, their models learn in micro batches and are evaluated after a certain period of time. Only after its performance is evaluated to be satisfactory that the model is deployed wider. For Weibo, their iteration cycle from learning to deploying model updates is 10 minutes.
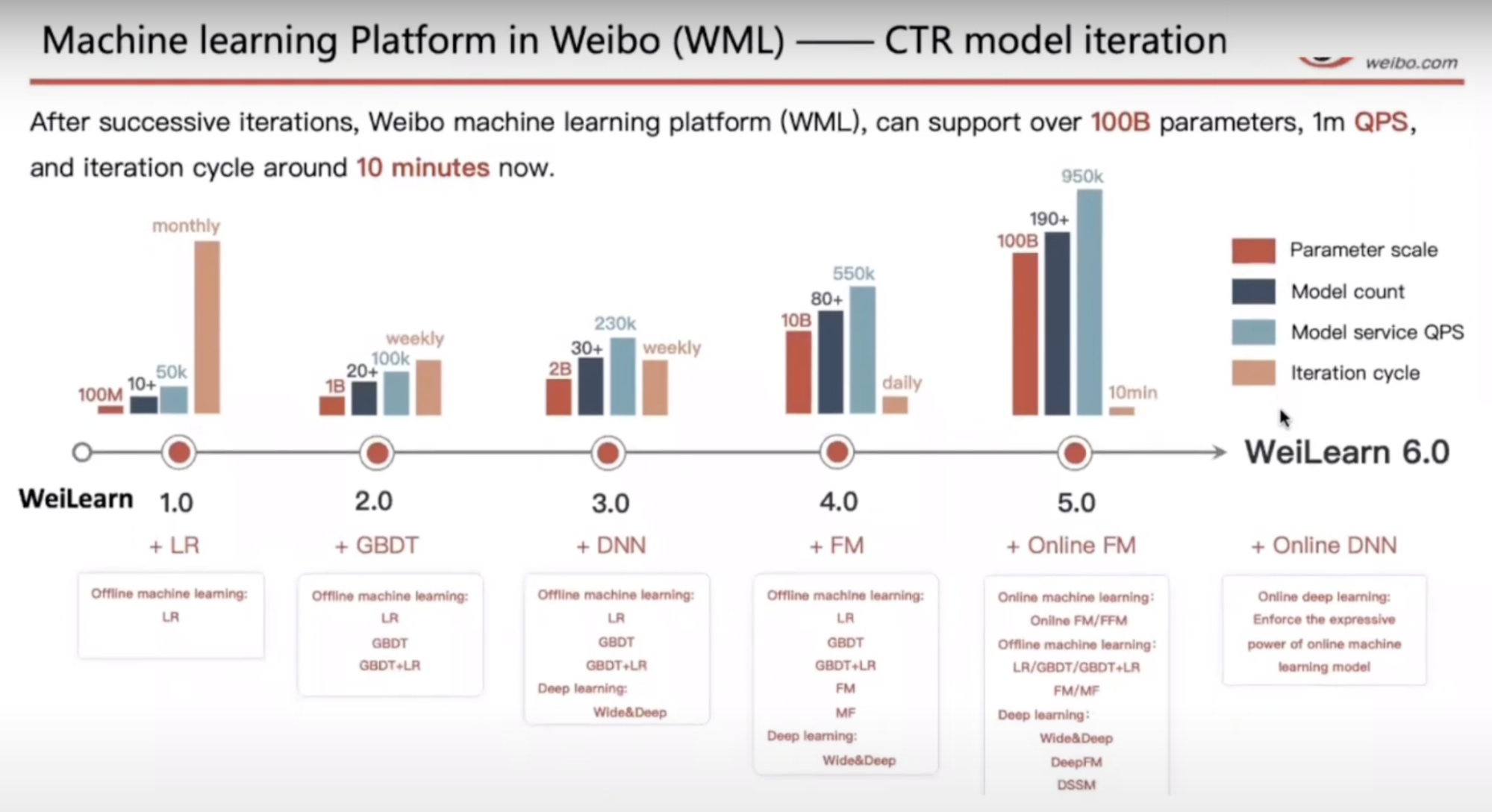
However, continual learning isn’t about the retraining frequency, but the manner in which the model is retrained.
Most companies do stateless retraining – the model is trained from scratch each time. Continual learning means allowing stateful training – the model continues training on new data (fine-tuning).
Once your infrastructure is set up to do stateful training, the training frequency is just a knob to twist. You can update your models once an hour, once a day, or you can update your models whenever your system detects a distribution shift.
Use cases
TikTok is incredibly addictive. Its secret lies in its recommendation systems that can learn your preferences quickly and suggest videos that you are likely to watch next, giving its users an incredible scrolling experience. It’s possible because ByteDance, the company behind TikTok, has set up a mature infrastructure that allows their recommendation systems to learn their user preferences (“user profiles” in their lingo) in real-time.
Recommendation systems are perfect candidates for continual learning. They have natural labels – if a user clicks on a recommendation, it’s a correct prediction. Not all recommendation systems need continual learning. User preferences for items like houses, cars, flights, hotels are unlikely to change from a minute to the next, so it would make little sense for systems to continually learn. However, user preferences for online content – videos, articles, news, tweets, posts, memes – can change very quickly (“I just read that octopi sometimes punch fish for no reason and now I want to see a video of it”). As preferences for online content change in real-time, ads systems also need to be updated in real-time to show relevant ads.
Continual learning is crucial for systems to adapt to rare events. Consider online shopping on Black Friday. Because Black Friday happens only once a year, there’s no way Amazon or other ecommerce sites can get enough historical data to learn how users are going to behave that day, so their systems need to continually learn on that day to adapt.
Or consider Twitter search when someone famous tweets something stupid. For example, as soon as the news about “Four Seasons Total Landscaping” went live, many people were going to search “total landscaping”. If your system doesn’t immediately learn that “total landscaping” here refers to the press conference, your users are going to get a lot of gardening recommendations.
Continual learning can also help with the cold start problem. A user just joined your app and you have no information on them yet. If you don’t have the capacity for any form of continual learning, you’ll have to serve your users generic recommendations until the next time your model is trained offline.
Solutions
Since continual learning is still fairly new and most companies who are doing it aren’t talking publicly about it in detail yet, there’s no standard solution.
Continual learning doesn’t mean “no batch training”. The companies that have most successfully used continual learning also train their models offline in parallel and then combine the online version with the offline version.
Challenges
There are many challenges facing continual learning, both theoretical and practical.
Theoretical
Continual learning flips a lot of what we’ve learned about machine learning on its head. In introductory machine learning classes, students are probably taught different versions of “train your model with a sufficient number of epochs until convergence.” In continual learning, there’s no epoch – your model sees each data point only once. There’s no such thing as convergence either. Your underlying data distribution keeps on shifting. There’s nothing stationary to converge to.
Another theoretical challenge for continual learning is model evaluation. In traditional batch training, you evaluate your models on stationary held out test sets. If a new model performs better than the existing model on the same test set, we say the new model is better. However, the goal of continual learning is to adapt your model to constantly changing data. If your updated model is trained to adapt to data now, and we know that data now is different from data in the past, it wouldn’t make sense to use old data to test your updated model.
Then how do we know that the model trained on data from the last 10 minutes is better than the model trained on data from 20 minutes ago? We have to compare these two models on current data. Online training demands online evaluation, but serving a model that hasn’t been tested to users sounds like a recipe for disaster.
Many companies do it anyway. New models are first subject to offline tests to make sure they aren’t disastrous, then evaluated online in parallel with the existing models via a complex A/B testing system. Only when a model is shown to be better than an existing model in some metrics the company cares about that it can be deployed wider. (Don’t get me started on choosing a metric for online evaluation).
Practical
There are not yet standard infrastructures for online training. Some companies have converged to streaming architecture with parameter servers, but other than that, companies that do online training that I’ve talked to have to build a lot of their infrastructures in house. I’m reluctant to discuss this online since some companies asked me to keep this information confidential because they’re building solutions for them – it’s their competitive advantage.
The MLOps race between the US and China
I’ve read a lot about the AI race between the US and China, but most comparisons seem to focus on the number of research papers, patents, citations, funding. Only after I’ve started talking to both American and Chinese companies about real-time machine learning that I noticed a staggering difference in their MLOps infrastructures.
Few American Internet companies have attempted continual learning, and even among these companies, continual learning is used for simple models such as logistic regression. My impression from both talking directly to Chinese companies and talking with people who have worked with companies in both countries is that continual learning is more common in China, and Chinese engineers are more eager to make the jump. You can see some of the conversations here and here.
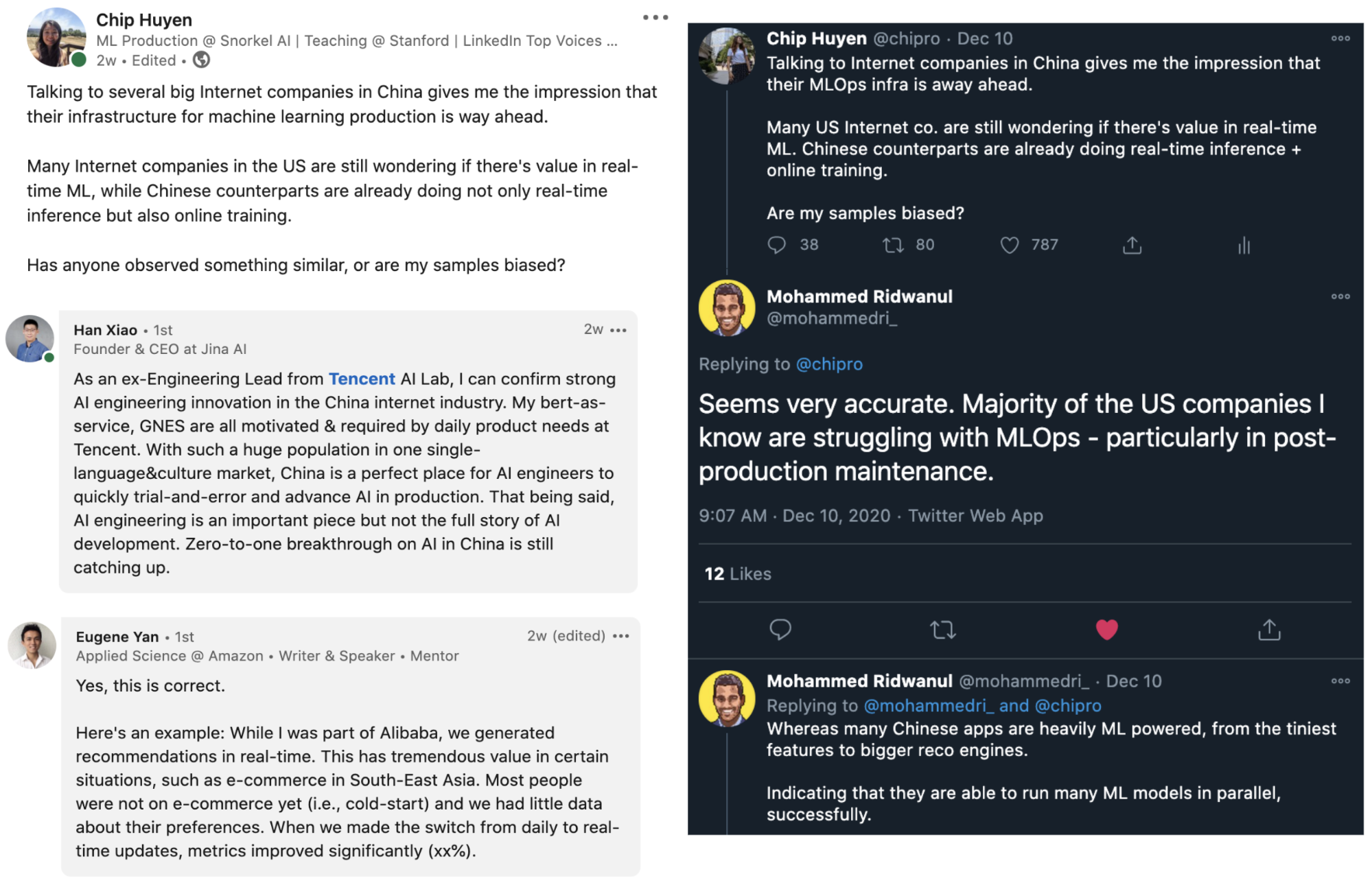
Conclusion
Machine learning is going real-time, whether you’re ready or not. While the majority of companies are still debating whether there’s value in online inference and continual learning, some of those who do it correctly have already seen returns on investment, and their real-time algorithms might be a major contributing factor that helps them stay ahead of their competitors.
I have a lot more thoughts on real-time machine learning but this post is already long. If you’re interested in chatting about this, get in touch!
Acknowledgments
This post is a synthesis of many conversations with the following wonderful engineers and academics. I’d like to thank Robert Metzger, Neil Lawrence, Savin Goyal, Zhenzhong Xu, Ville Tuulos, Dat Tran, Han Xiao, Hien Luu, Ledio Ago, Peter Skomoroch, Piero Molino, Daniel Yao, Jason Sleight, Becket Qin, Tien Le, Abraham Starosta, Will Deaderick, Caleb Kaiser, Miguel Ramos.
There are several more people who have chosen to stay anonymous. Without them, this post would be incomplete.
Thanks Luke Metz for being an amazing first reader!
I want to devote a lot of my time to learning. I’m hoping to find a group of people with similar interests and learn together. Here are some of the topics that I want to learn:
- ML on the edge (phones, tablets, browsers)
- Online predictions and continual learning for machine learning
- MLOps in general
If you want to learn any of the above topics, join our Discord chat. We’ll be sharing learning resources and strategies. We might even host learning sessions and discussions if there’s interest. Serious learners only!
For a follow up of this post, see Real-time machine learning: challenges and solutions (2022).