Multimodality and Large Multimodal Models (LMMs)
For a long time, each ML model operated in one data mode – text (translation, language modeling), image (object detection, image classification), or audio (speech recognition).
However, natural intelligence is not limited to just a single modality. Humans can read, talk, and see. We listen to music to relax and watch out for strange noises to detect danger. Being able to work with multimodal data is essential for us or any AI to operate in the real world.
OpenAI noted in their GPT-4V system card that “incorporating additional modalities (such as image inputs) into LLMs is viewed by some as a key frontier in AI research and development.”
Incorporating additional modalities to LLMs (Large Language Models) creates LMMs (Large Multimodal Models). Not all multimodal systems are LMMs. For example, text-to-image models like Midjourney, Stable Diffusion, and Dall-E are multimodal but don’t have a language model component. Multimodal can mean one or more of the following:
- Input and output are of different modalities (e.g. text-to-image, image-to-text)
- Inputs are multimodal (e.g. a system that can process both text and images)
- Outputs are multimodal (e.g. a system that can generate both text and images)
This post covers multimodal systems in general, including LMMs. It consists of 3 parts.
- Part 1 covers the context for multimodality, including why multimodal, different data modalities, and types of multimodal tasks.
- Part 2 discusses the fundamentals of a multimodal system, using the examples of CLIP, which lays the foundation for many future multimodal systems, and Flamingo, whose impressive performance gave rise to LMMs.
- Part 3 discusses some active research areas for LMMs, including generating multimodal outputs and adapters for more efficient multimodal training, covering newer multimodal systems such as BLIP-2, LLaVA, LLaMA-Adapter V2, LAVIN, etc.
The post is long. Feel free to skip to the sections most interesting to you.
⚠ Ambiguous terminology ⚠
Multimodal data can also refer to multimodal distributions, e.g. bimodal distribution, which is different from multimodal data in this post.
Table of contents
Part 1. Understanding Multimodal
…. Why multimodal
…. Data modalities
…. Multimodal tasks
…….. Generation
…….. Vision-language understanding
Part 2. Fundamentals of Multimodal Training
…. CLIP: Contrastive Language-Image Pre-training
…….. CLIP’s high-level architecture
…….. Natural language supervision
…….. Contrastive learning
…….. CLIP applications
…. Flamingo: the dawns of LMMs
…….. Flamingo’s high-level architecture
…….. Data
…….. Flamingo’s vision encoder
…….. Flamingo’s language model
…. TL;DR: CLIP vs. Flamingo
Part 3. Research Directions for LMMs
…. Incorporating more data modalities
…. Multimodal systems for instruction-following
…. Adapters for more efficient multimodal training
…. Generating multimodal outputs
Conclusion
Resources
Part 1. Understanding Multimodal
Why multimodal
Many use cases are impossible without multimodality, especially those in industries that deal with a mixture of data modalities such as healthcare, robotics, e-commerce, retail, gaming, etc.
Not only that, incorporating data from other modalities can help boost model performance. Shouldn’t a model that can learn from both text and images perform better than a model that can learn from only text or only image?
Multimodal systems can provide a more flexible interface, allowing you to interact with them in whichever way works best for you at the moment. Imagine you can ask a question by typing, talking, or just pointing your camera at something.
One use case that I’m especially excited about, is that multimodality can also enable visually impaired people to browse the Internet and also navigate the real world.

Data modalities
Different data modes are text, image, audio, tabular data, etc. One data mode can be represented or approximated in another data mode. For example:
- Audio can be represented as images (mel spectrograms).
- Speech can be transcribed into text, though its text-only representation loses information such as volume, intonation, pauses, etc.
- An image can be represented as a vector, which, in turn, can be flattened and represented as a sequence of text tokens.
- A video is a sequence of images plus audio. ML models today mostly treat videos as sequences of images. This is a severe limitation, as sounds have proved to be just as important as visuals for videos. 88% of TikTok users shared that sound is essential for their TikTok experience.
- A text can be represented as an image if you simply take a picture of it.
- A data table can be converted into a chart, which is an image.
How about other data modalities?
All digital data formats can be represented using bitstrings (strings of 0 and 1) or bytestrings. A model that can effectively learn from bitstrings or bytestrings will be very powerful, and it can learn from any data mode.
There are other data modalities we haven’t touched on, such as graphs and 3D assets. We also haven’t touched on the formats used to represent smell and touch (haptics).
In ML today, audio is still largely treated as a voice-based alternative to text. The most common use cases for audio are still speech recognition (speech-to-text) and speech synthesis (text-to-speech). Non-speech audio use cases, e.g. music generation, are still pretty niche. See the fake Drake & Weeknd song and MusicGen model on HuggingFace.
Image is perhaps the most versatile format for model inputs, as it can be used to represent text, tabular data, audio, and to some extent, videos. There’s also so much more visual data than text data. We have phones/webcams that constantly take pictures and videos today.
Text is a much more powerful mode for model outputs. A model that can generate images can only be used for image generation, whereas a model that can generate text can be used for many tasks: summarization, translation, reasoning, question answering, etc.
For simplicity, we’ll focus on 2 modalities: images and text. The learnings can be somewhat generalized to other modalities.
Multimodal tasks
To understand multimodal systems, it’s helpful to look at the tasks they are built to solve. In literature, I commonly see vision-language tasks divided into two groups: generation and vision-language understanding (VLU), which is the umbrella term for all tasks that don’t require generation. The line between these two groups is blurred, as being able to generate answers requires understanding too.
Generation
For generative tasks, the output can be unimodal (e.g. text, image, 3D rendering) or multimodal. While unimodal outputs are common today, multimodal outputs are still shaping up. We’ll discuss multimodal outputs at the end of this post.
Image generation (text-to-image synthesis)
This category is straightforward. Examples: Dall-E, Stable Diffusion, and Midjourney.
Text generation
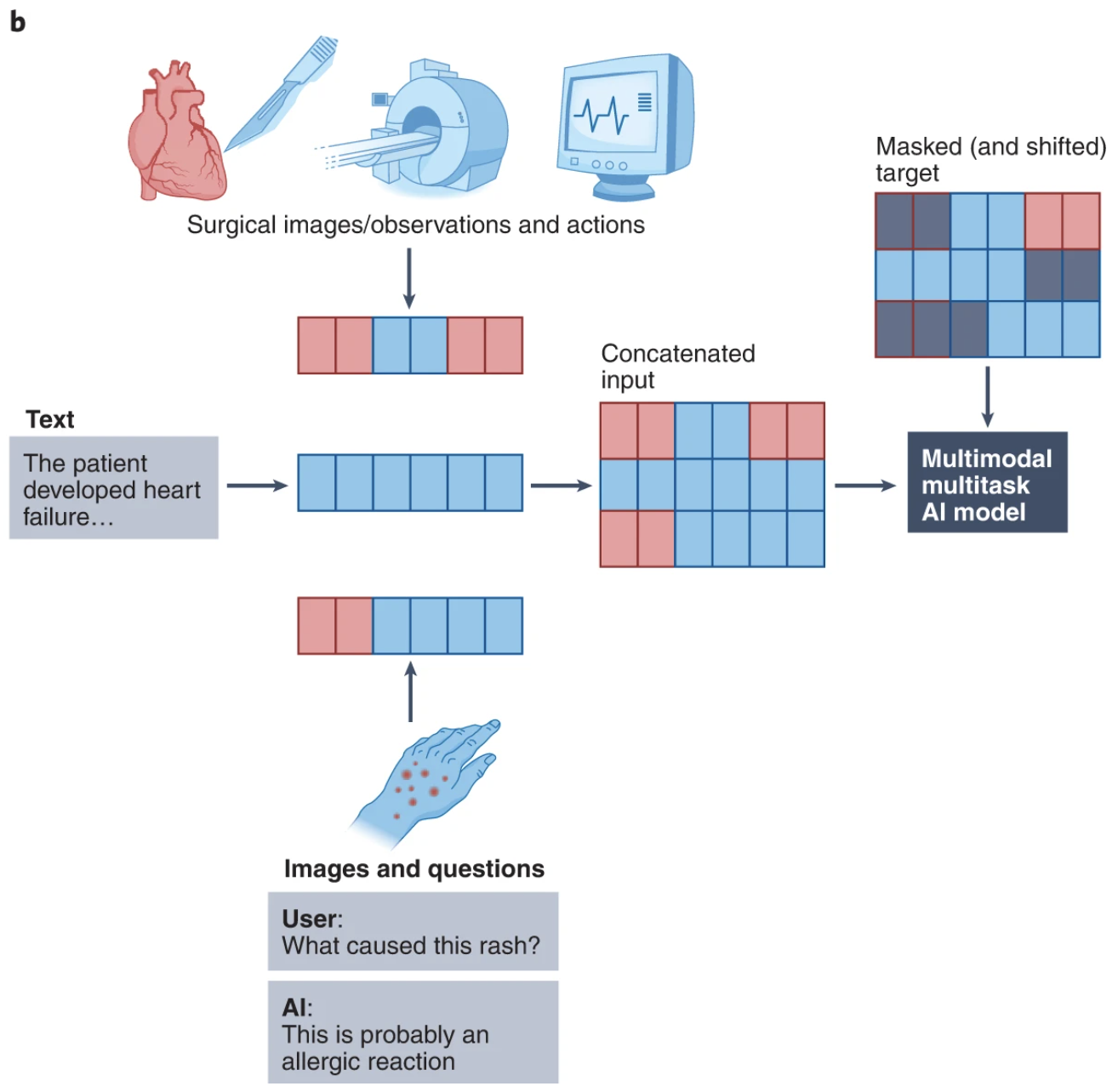
A common text generation task is visual question answering. Instead of relying only on text for the context, you can give the model both text and images. Imagine you can point your camera to anything and ask questions like: “My car won’t start. What’s wrong with it?”, “How to make this dish?”, or “What is this meme about?”.
Another common use case is image captioning, which can be used as part of a text-based image retrieval system. An organization might have millions, if not billions, of images: product images, graphs, designs, team pictures, promotional materials, etc. AI can automatically generate captions and metadata for them, making it easier to find the exact images you want.
Vision-language understanding
We’ll zoom into two task types: classification and text-based image retrieval (TBIR).
Classification
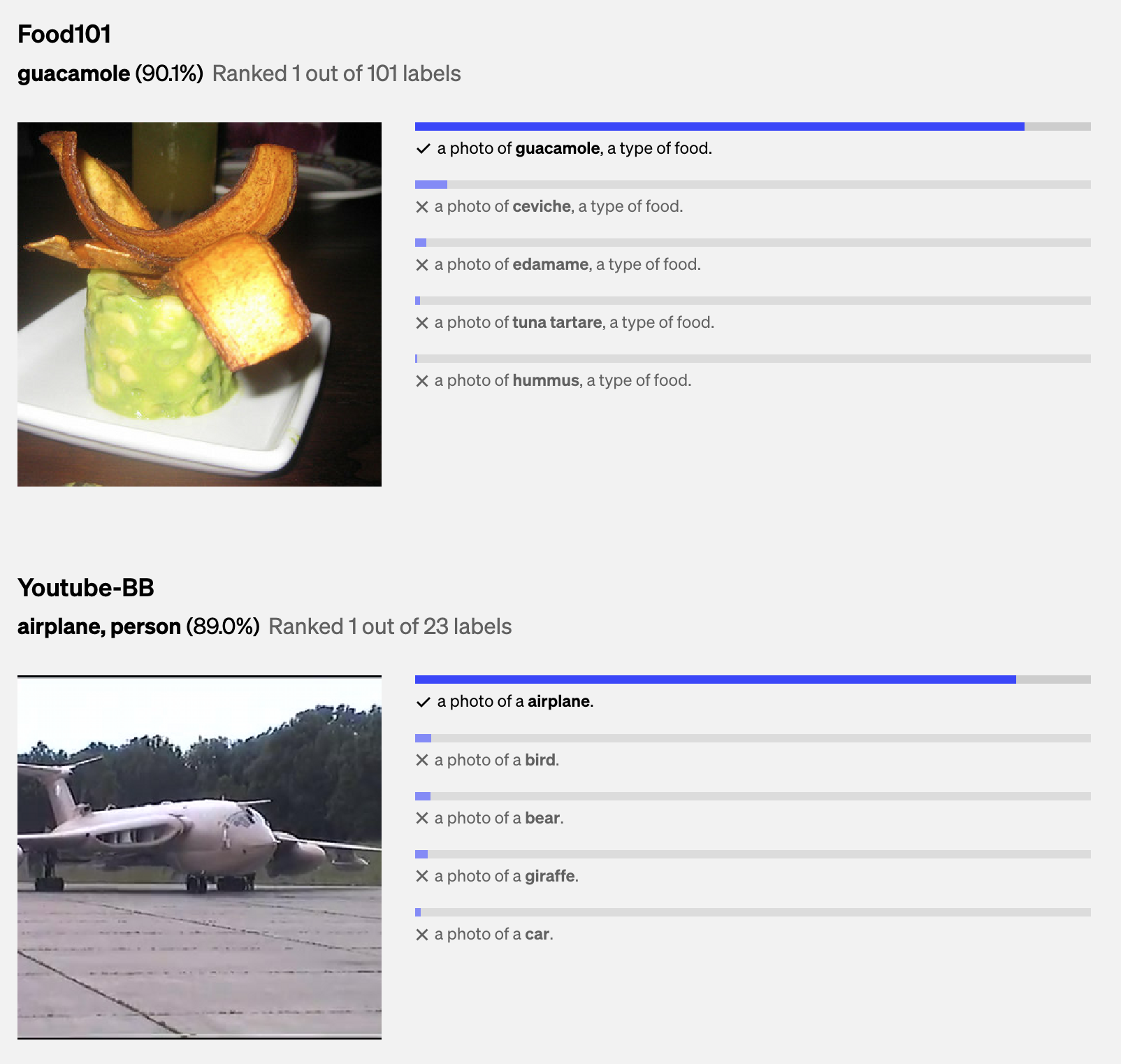
Classification models can only generate outputs that belong to a pre-determined list of classes. This works when you only care about a fixed number of outcomes. For example, an OCR system only needs to predict if a visual is one of the known characters (e.g. a digit or a letter).
Side note: An OCR system processes data at the character level. When used together with a system that can understand the broader context, it can improve use cases such as allowing you to “talk” to any textbook, contract, assembly instructions, etc.

One related task to classification is image-to-text retrieval: given an image and a pool of pre-defined texts, find the text that’s most likely to accompany the image. This can be helpful for product image search, i.e. retrieving product reviews from a picture.
Text-based image retrieval (image search)
Image search matters not only for search engines but also for enterprises to be able to search through all their internal images and documents. Some people call text-based image retrieval “text-to-image retrieval”.
There are several approaches to text-based image retrieval. Two of them are:
- Generate captions and metadata for each image, either manually or automatically (see image captioning in Text generation). Given a text query, find images whose captions/metadata are closest to this text query.
- Train a joint embedding space for both images and text. Given a text query, generate an embedding for this query, and find all images whose embeddings are closest to this embedding.
The second approach is more flexible, and I believe will be more widely used. This approach requires having a strong joint embedding space for both vision and language, like the one that OpenAI’s CLIP developed.
Part 2. Fundamentals of Multimodal Training
Given the existence of so many amazing multimodal systems, a challenge of writing this post is choosing which systems to focus on. In the end, I decided to focus on two models: CLIP (2021) and Flamingo (2022) both for their significance as well as availability and clarity of public details.
- CLIP was the first model that could generalize to multiple image classification tasks with zero- and few-shot learning.
- Flamingo wasn’t the first large multimodal model that could generate open-ended responses (Salesforce’s BLIP came out 3 months prior). However, Flamingo’s strong performance prompted some to consider it the GPT-3 moment in the multimodal domain.
Even though these two models are older, many techniques they use are still relevant today. I hope they serve as the foundation to understanding newer models. The multimodal space is evolving repaidly, with many new ideas being developed. We’ll go over these newer models in Part 3.
At a high level, a multimodal system consists of the following components:
- An encoder for each data modality to generate the embeddings for data of that modality.
- A way to align embeddings of different modalities into the same multimodal embedding space.
- [Generative models only] A language model to generate text responses. Since inputs can contain both text and visuals, new techniques need to be developed to allow the language model to condition its responses on not just text, but also visuals.
Ideally, as many of these components should be pretrained and reusable as possible.
CLIP: Contrastive Language-Image Pre-training
CLIP’s key contribution is its ability to map data of different modalities, text and images, into a shared embedding space. This shared multimodal embedding space makes text-to-image and image-to-text tasks so much easier.
Training this multimodal embedding space also produced a strong image encoder, which allows CLIP to achieve competitive zero-shot performance on many image classification tasks. This strong image encoder can be used for many other tasks: image generation, visual question answering, and text-based image retrieval. Flamingo and LLaVa use CLIP as their image encoder. DALL-E uses CLIP to rerank generated images. It’s unclear if GPT-4V uses CLIP.
CLIP leveraged natural language supervision and contrastive learning, which allowed CLIP to both scale up their data and make training more efficient. We’ll go over why/how these two techniques work.
CLIP's high-level architecture
For the image encoder, the authors experimented with both ResNet and ViT. Their best-performing model is ViT-L/14@336px:
- Large vision transformer (ViT-L)
- 14 patches (each image is divided into 14x14 pixel patches/sub-images)
- on 336x336 pixel input
For the text encoder, CLIP uses a Transformer model similar to GPT-2 but smaller. Their base model has only 63M parameters with 8 attention heads. The authors found CLIP’s performance to be less sensitive to the capacity of the text encoder.
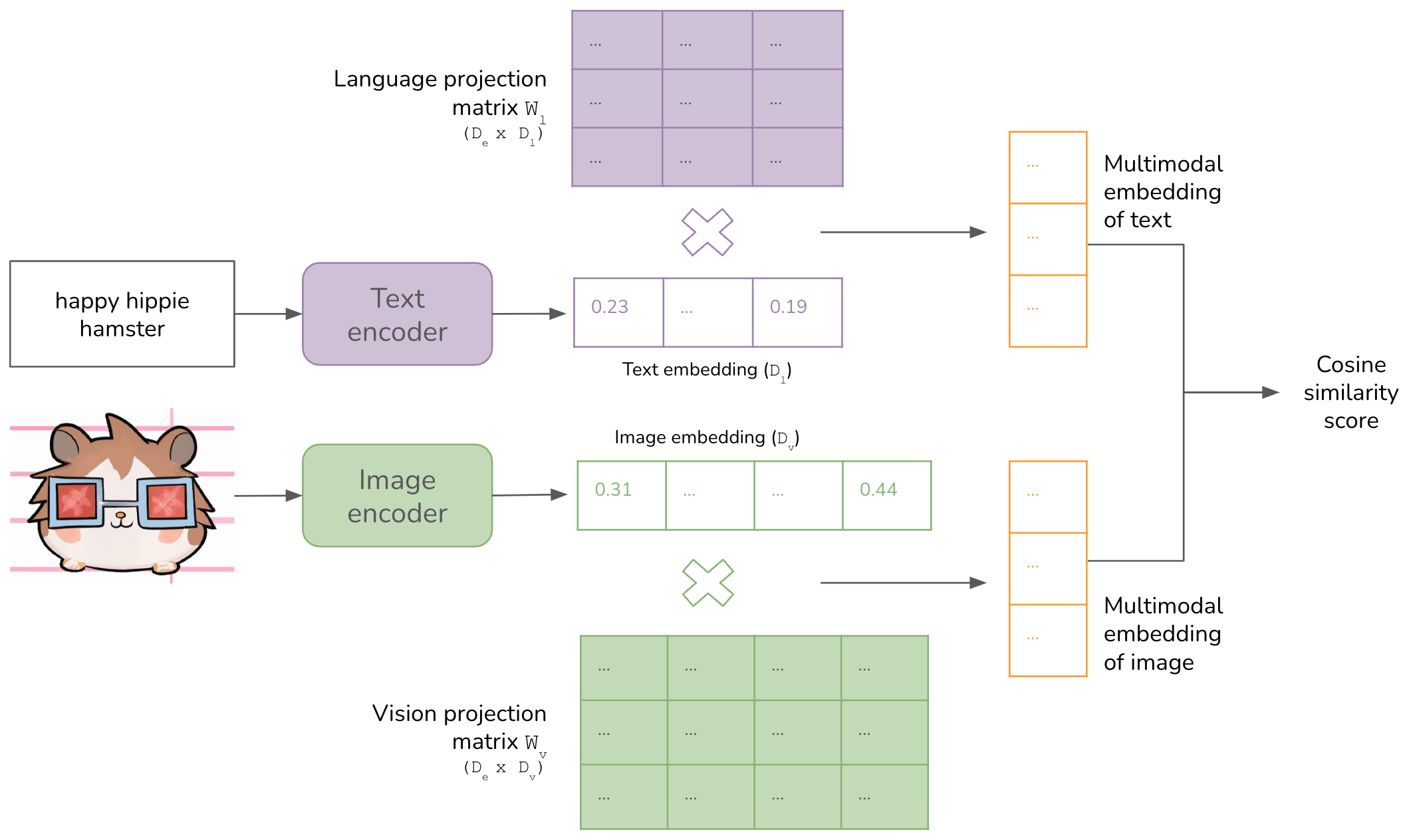
Embeddings generated by the image encoder and text encoder are projected into the same embedding space using two projection matrices \(W_v\) and \(W_l\).
- Given an image embedding \(V_i\), the corresponding multimodal embedding is computed as: \(W_vV_i\).
- Given a text embedding \(L_i\), the corresponding multimodal embedding is computed as: \(W_lL_i\).
When people say CLIP embeddings, they either refer to these multimodal embeddings or the embeddings generated by CLIP’s image encoder.
Natural language supervision
For many years, image models were trained with manually annotated (image, text) datasets (e.g. ImageNet, MS COCO). This isn’t scalable. Manual annotation is time-consuming and expensive.
The CLIP paper noted that none of the then-available (image, text) datasets was big and high quality enough. They created their own dataset – 400M (image, text) pairs – as follows.
- Construct a list of 500,000 queries. Queries are common words, bigrams, and titles of popular Wikipedia articles.
- Find images matching these queries (string and substring match). The paper mentioned this search did NOT happen on search engines but didn’t specify where. My theory is that since OpenAI already scraped the entire Internet for their GPT models, they probably just queried their internal database.
- Each image is paired with a text that co-occurs with it (e.g. captions, comments) instead of the query since queries are too short to be descriptive.
Because some queries are more popular than others, to avoid data imbalance, they used at most 20K images for a query.
Contrastive learning
Pre-CLIP, most vision-language models were trained using a classifier or language model objectives. Contrastive objective is a clever technique that allows CLIP to scale and generalize to multiple tasks.
We’ll show why the constrastive objective works better for CLIP using an example task of image captioning: given an image, generate a text that describes it.
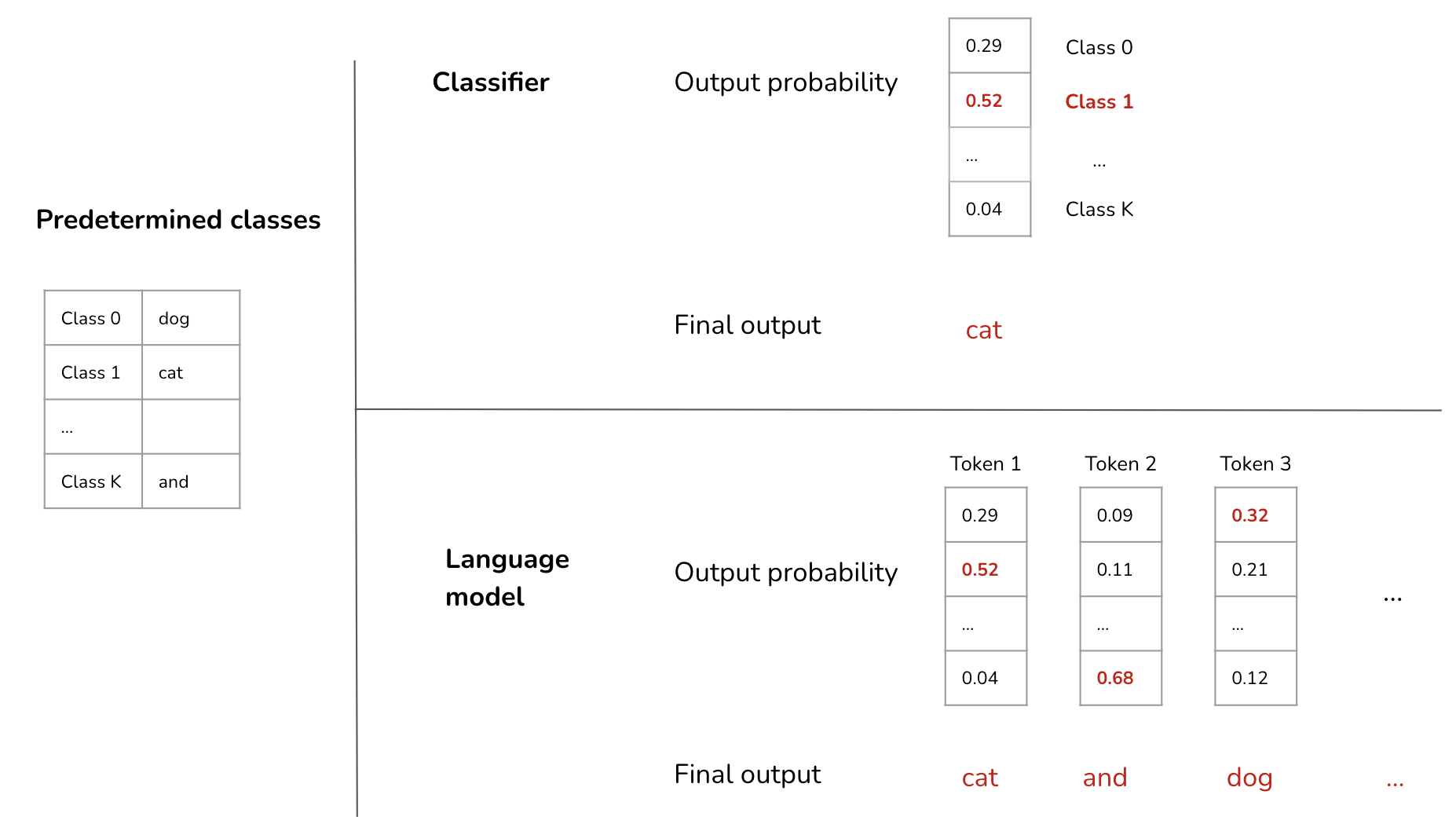
Classifier objective
A classifier predicts the correct class among a predetermined list of classes. This works when the output space is finite. Previous models that work with (image, text) pair datasets all had this limitation. For example, models working with ILSVRC-2012 limited themselves to 1,000 classes, and JFT-300M to 18,291 classes.
This objective limits not only the model’s capacity to output meaningful responses but also its capacity for zero-shot learning. Say, if the model was trained to predict among 10 classes, it won’t work for a task that has 100 classes.
Language model objective
If a classifier outputs only one class for each input, a language model outputs a sequence of classes. Each generated class is called a token. Each token is from a predetermined list, the vocabulary, of the language model.
Contrastive objective
While the language model objective allows for vastly more flexible outputs, CLIP authors noted this objective made the training difficult. They hypothesized that this is because the model tries to generate exactly the text accompanying each image, while many possible texts can accompany an image: alt-text, caption, comments, etc.
For example, in the Flickr30K dataset, each image has 5 captions provided by human annotators, and the captions for the same image can be very different.

Contrastive learning is to overcome this challenge. Instead of predicting the exact text of each image, CLIP was trained to predict whether a text is more likely to accompany an image than other texts.
For each batch of \(N\) (image, text) pairs, the model generates N text embeddings and N image embeddings.
- Let \(V_1, V_2, ..., V_n\) be the embeddings for the \(N\) images.
- Let \(L_1, L_2, ..., L_n\) be the embeddings for the \(N\) texts.
CLIP computes the cosine similarity scores of the \(N^2\) possible (\(V_i, L_j\)) pairings. The model is trained to maximize the similarity scores of the \(N\) correct pairings while minimizing the scores of the \(N^2 - N\) incorrect pairings. For CLIP, \(N = 32,768\).
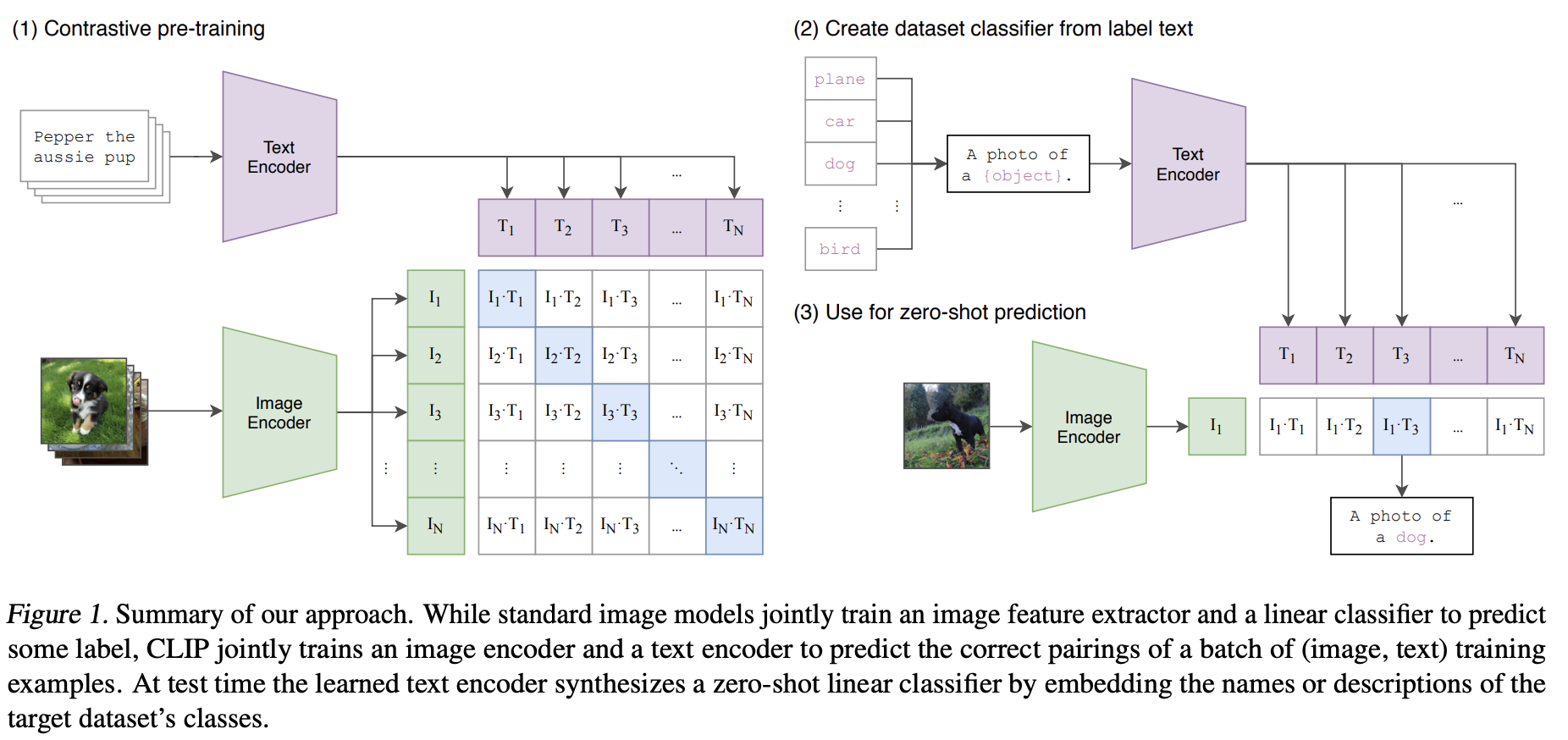
Another way to look at this is that each training batch of CLIP is two classification tasks.
-
Each image can be paired with N possible texts, and the model tries to predict the correct one. This is the same setup as image-to-text retrieval.
\[L_{\text{contrastive:txt2im}} = -\frac{1}{N}\sum_i^N\log(\frac{\exp(L_i^TV_i\beta)}{\sum_j^N\exp(L_i^TV_j\beta)})\] -
Each text can be paired with N possible images, and the model tries to predict the correct image. This is the same setup as text-to-image retrieval.
\[L_{\text{contrastive:im2txt}} = -\frac{1}{N}\sum_i^N\log(\frac{\exp(V_i^TL_i\beta)}{\sum_j^N\exp(V_i^TL_j\beta)})\]
The sum of these two losses is minimized. 𝛽 is a trainable inverse temperature parameter.
This is what it all looks like in pseudocode.

CLIP authors found that the contrastive objective provided a 12x improvement in efficiency compared to the language model objective baseline while producing higher-quality image embeddings.
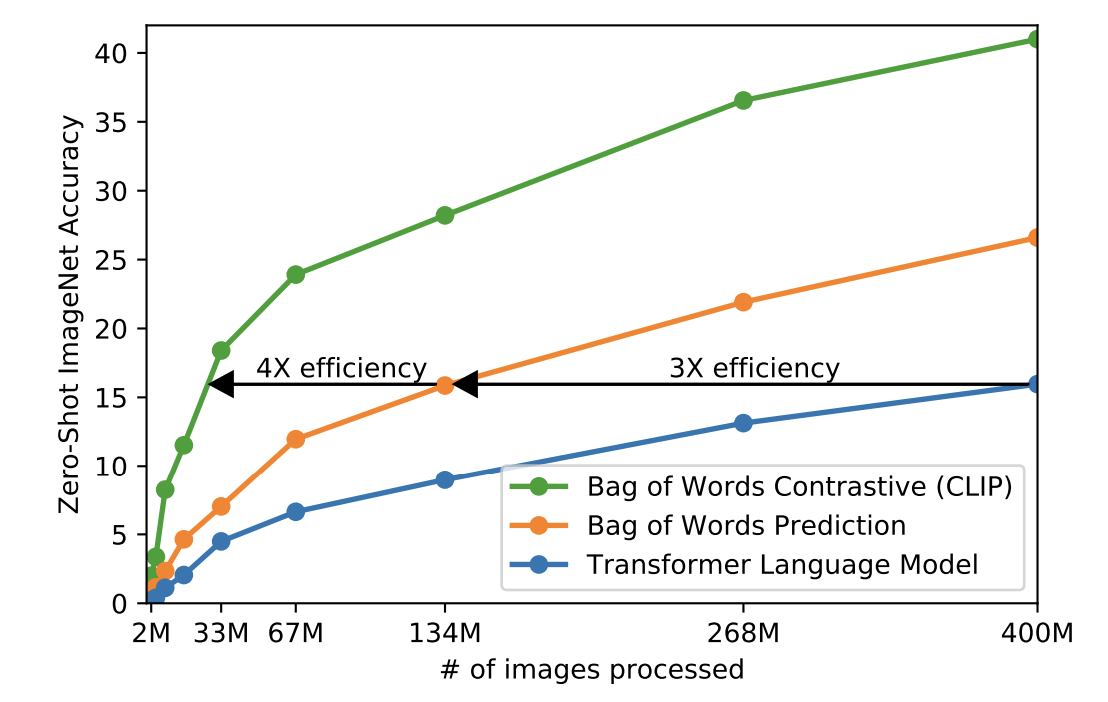
CLIP applications
Classification
Today, for many image classification tasks, CLIP is still a strong out-of-the-box baseline to be used as-is or fine-tuned.
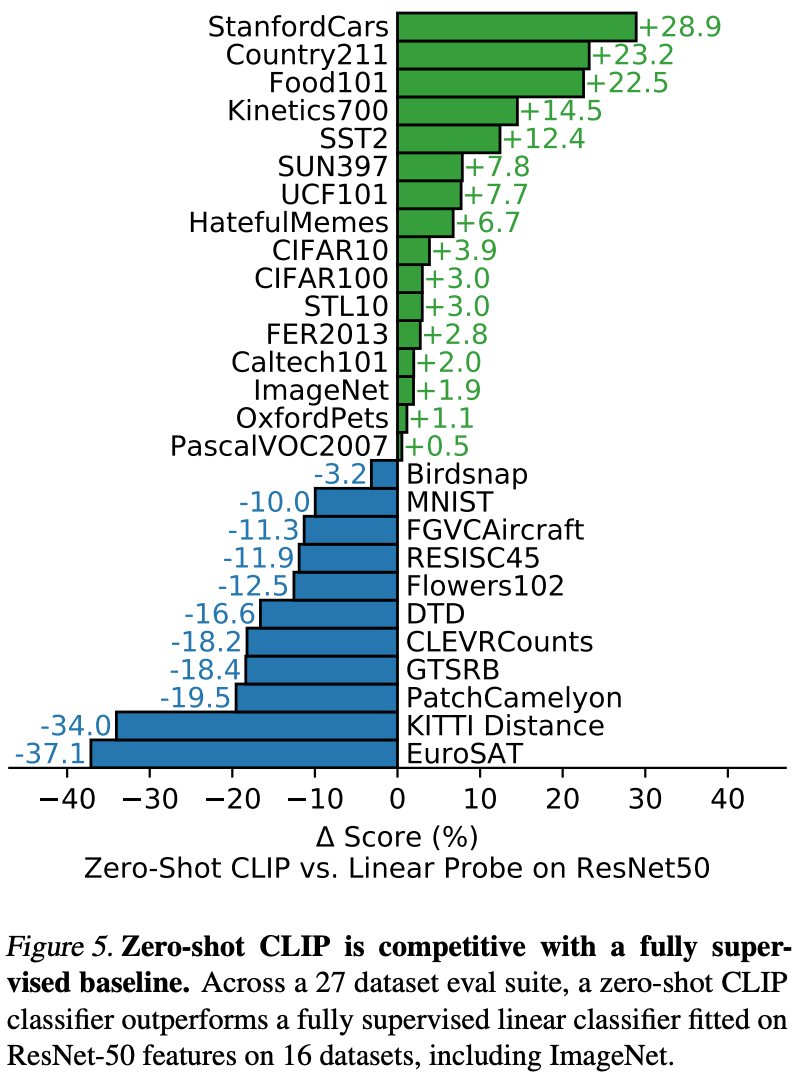
Text-based image retrieval
Since CLIP’s training process was conceptually similar to image-to-text retrieval and text-to-image retrieval, CLIP “displays significant promise for widely-applicable tasks like image retrieval or search.” However, “on image retrieval, CLIP’s performance relative to the overall state of the art is noticeably lower.”
There are attempts to use CLIP for image retrieval. For example, clip-retrieval package works as follows:
- Generate CLIP embeddings for all your images and store them in a vector database.
- For each text query, generate a CLIP embedding for this text.
- Query in the vector database for all images whose embeddings are close to this text query embedding.
Image generation
CLIP’s joint image-text embeddings are useful for image generation. Given a text prompt, DALL-E (2021) generates many different visuals and uses CLIP to rerank these visuals before showing the top visuals to users.
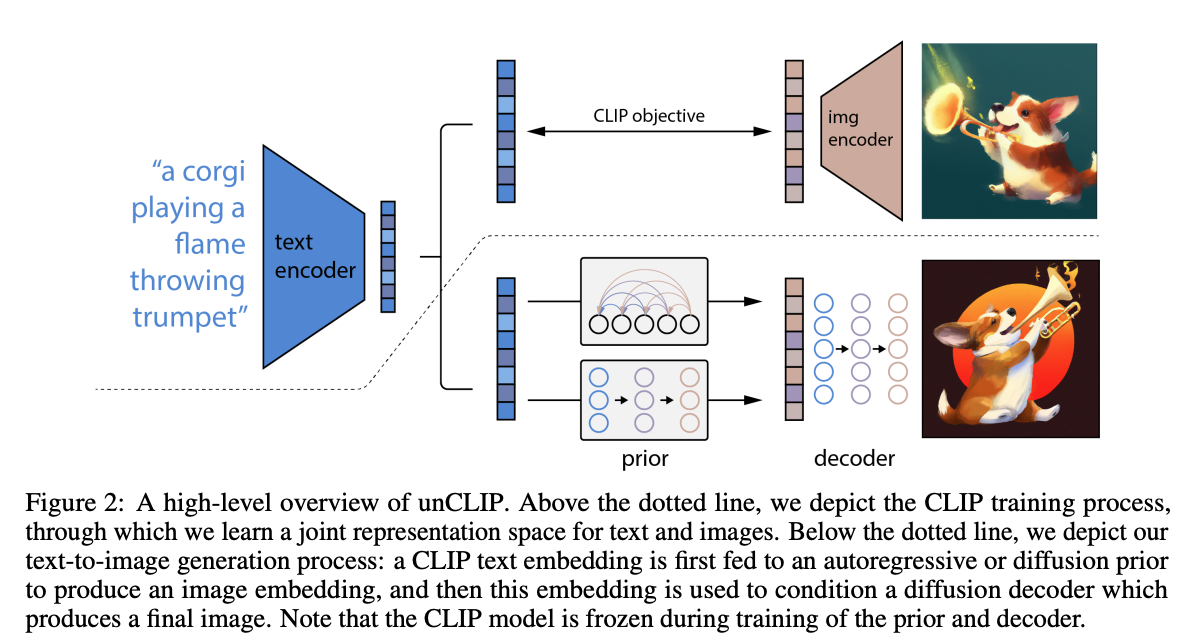
In 2022, OpenAI introduced unCLIP, a text-to-image synthesis model conditioned on CLIP latents. It consists of two main components:
- CLIP is trained and frozen. The pretrained CLIP model can generate embeddings for both text and images in the same embedding space.
- Two things happen at image generation:
- Use CLIP to generate embedding for this text.
- Use a diffusion decoder to generate images conditioned on this embedding.
Text generation: visual question answering, captioning
CLIP authors did attempt to create a model for text generation. One version they experimented with is called LM RN50. Though this model could generate text responses, its performance was consistently around 10% below CLIP’s best-performing model on all the vision-language understanding tasks that CLIP was evaluated on.
While today CLIP isn’t used directly for text generation, its image encoder is often the backbone for LMMs that can generate texts.
Flamingo: the dawns of LMMs
Unlike CLIP, Flamingo can generate text responses. In a reductive view, Flamingo is CLIP + a language model, with added techniques to make it possible for the language model to generate text tokens conditioned on both visual and text inputs.

Flamingo's high-level architecture
At a high level, Flamingo consists of 2 parts:
- Vision encoder: a CLIP-like model is trained using contrastive learning. The text encoder of this model is then discarded. The vision encoder is frozen to be used in the main model.
- Language model: Flamingo finetunes Chinchilla to generate text tokens, conditioned on visuals and text, using language model loss, with two additional components Perceiver Resampler and GATED XATTN-DENSE layers. We’ll discuss them later in this blog.
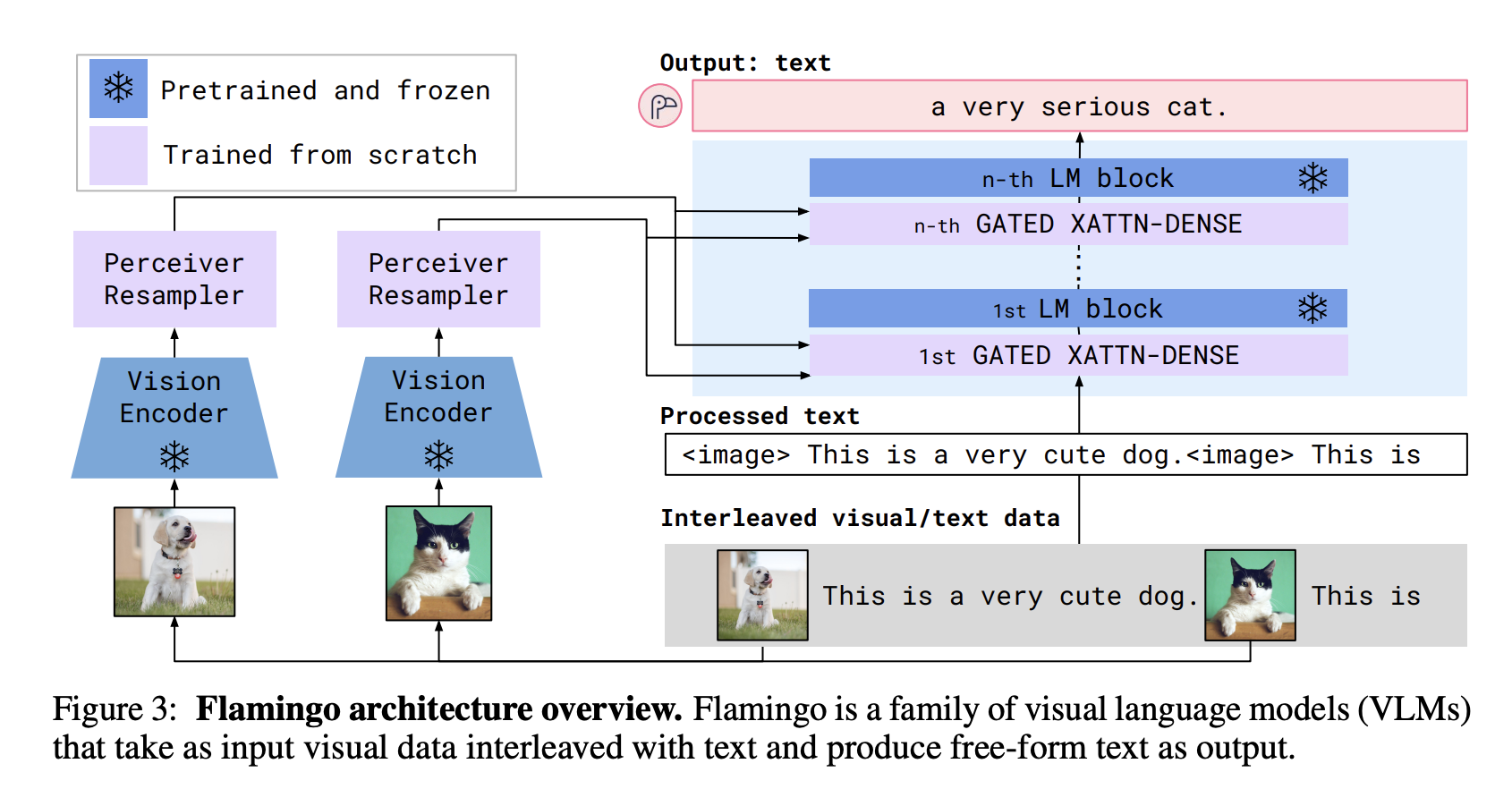
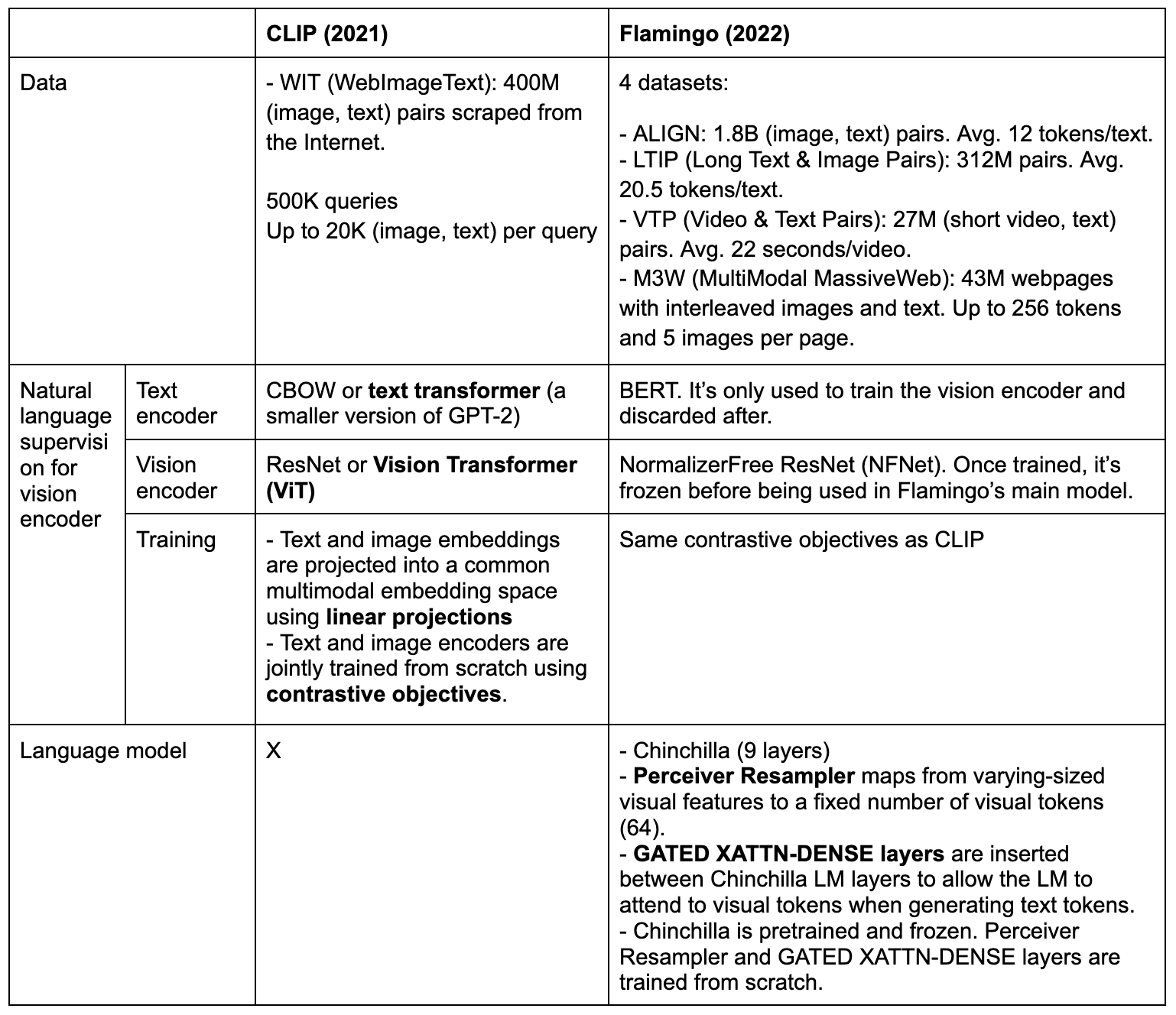
Data
Flamingo used 4 datasets: 2 (image, text) pair datasets, 1 (video, text) pair dataset, and 1 interleaved image and text dataset.

| Dataset | Type | Size | How | Training weight |
| M3W | Interleaved image and text dataset | 43M webpages | For each webpage, they sample a random subsequence of 256 tokens and take up to the first 5 images included in the sampled sequence. | 1.0 |
| ALIGN | (Image, text) pairs | 1.8B pairs | Texts are alt-texts, averaging 12 tokens/text. | 0.2 |
| LTIP | (Image, text) pairs | 312M pairs | Texts are long descriptions, averaging 20.5 tokens/text. | 0.2 |
| VTP | (Video, text) pairs | 27M short videos | ~22 seconds/video on average | 0.03 |
Flamingo's vision encoder
Flamingo first trains a CLIP-like model from scratch using contrastive learning. This component only uses the 2 (image, text) pair datasets, ALIGN and LTIP, totaling 2.1B (image, text) pairs. This is 5x larger than the dataset CLIP was trained on.
- For the text encoder, Flamingo uses BERT instead of GPT-2.
- For the vision encoder, Flamingo uses a NormalizerFree ResNet (NFNet) F6 model.
- Text and vision embeddings are meanpooled before being projected to the joint embedding space.
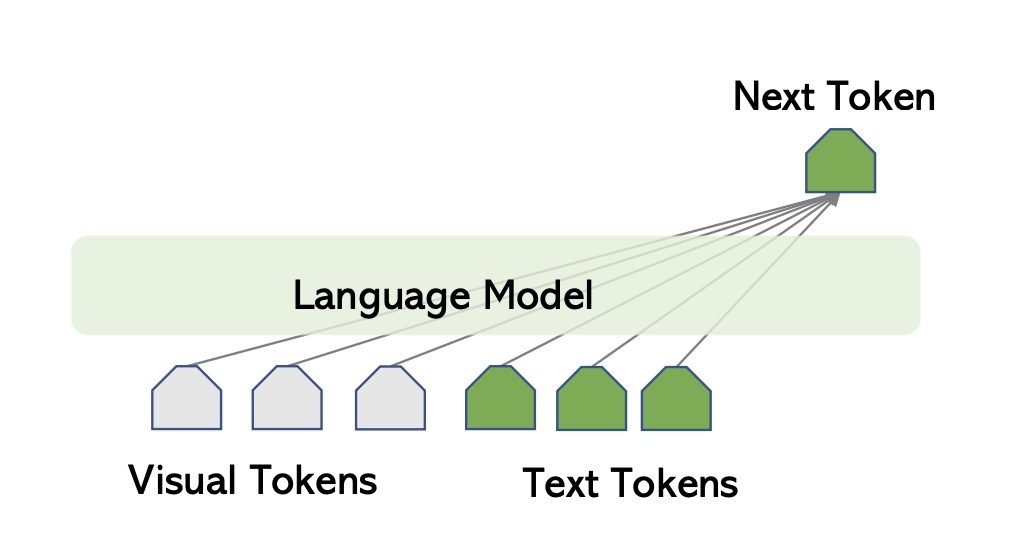
Flamingo's language model
Flamingo uses Chinchilla as their language model. More specifically, they freeze the 9 pretrained Chinchilla LM layers. A traditional language model predicts the next text token based on the preceding text tokens. Flamingo predicts the next text token based on both the preceding text and visual tokens.
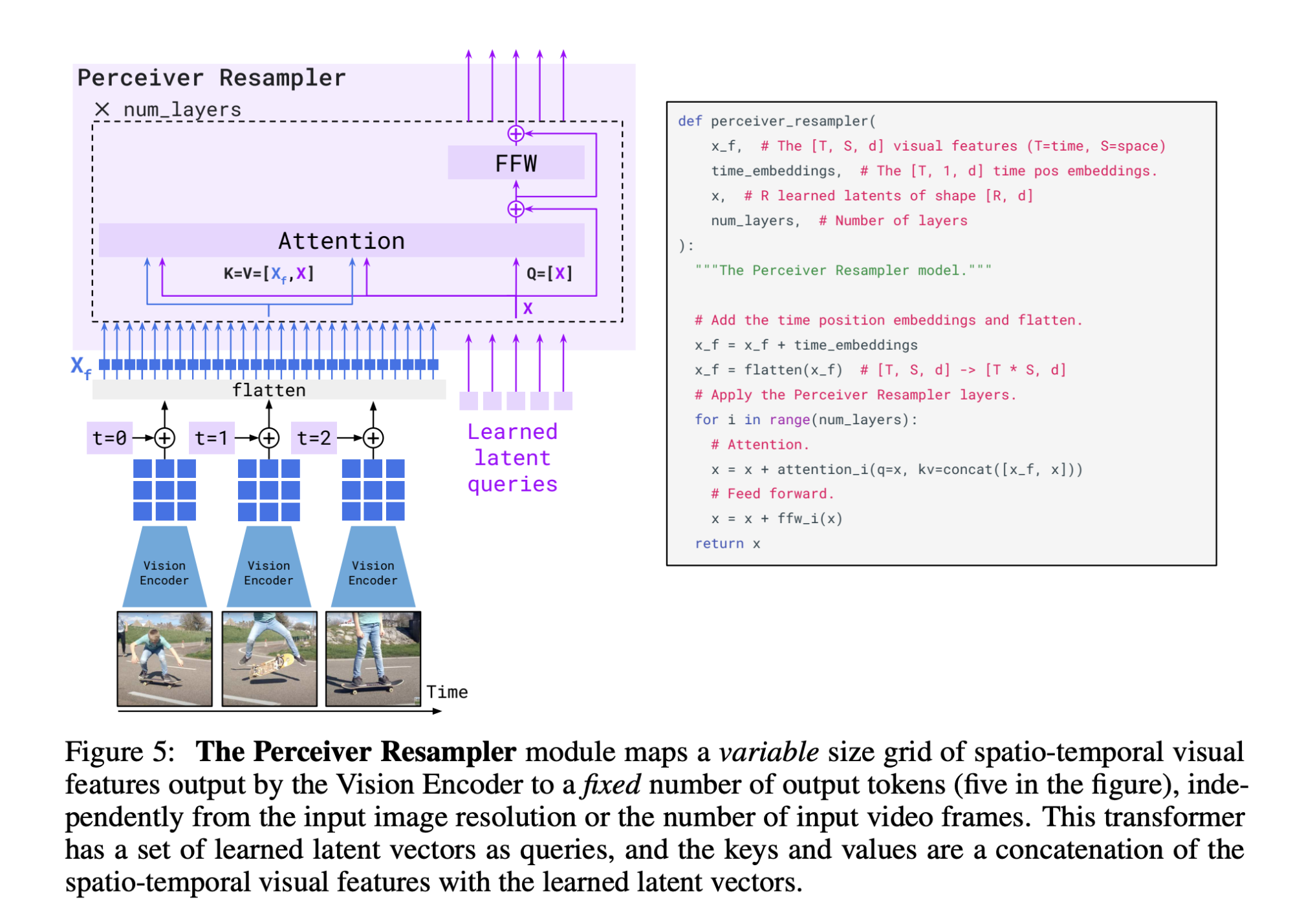
To be able to generate text conditioned on both text and visual inputs, Flamingo relied on Perceiver Resampler and GATED XATTN-DENSE layers.
Perceiver Resampler
As the visual inputs can be both images and videos, the vision encoder can produce a variable number of image or video features. Perceiver Resampler converts these variable features into a consistent 64 visual outputs.
Interestingly enough, while training the vision encoder, the resolution used was 288 x 288. However, at this phase, visual inputs are resized to 320 × 320. It’s been shown that a higher test-time resolution can lead to improved performance when using CNNs.
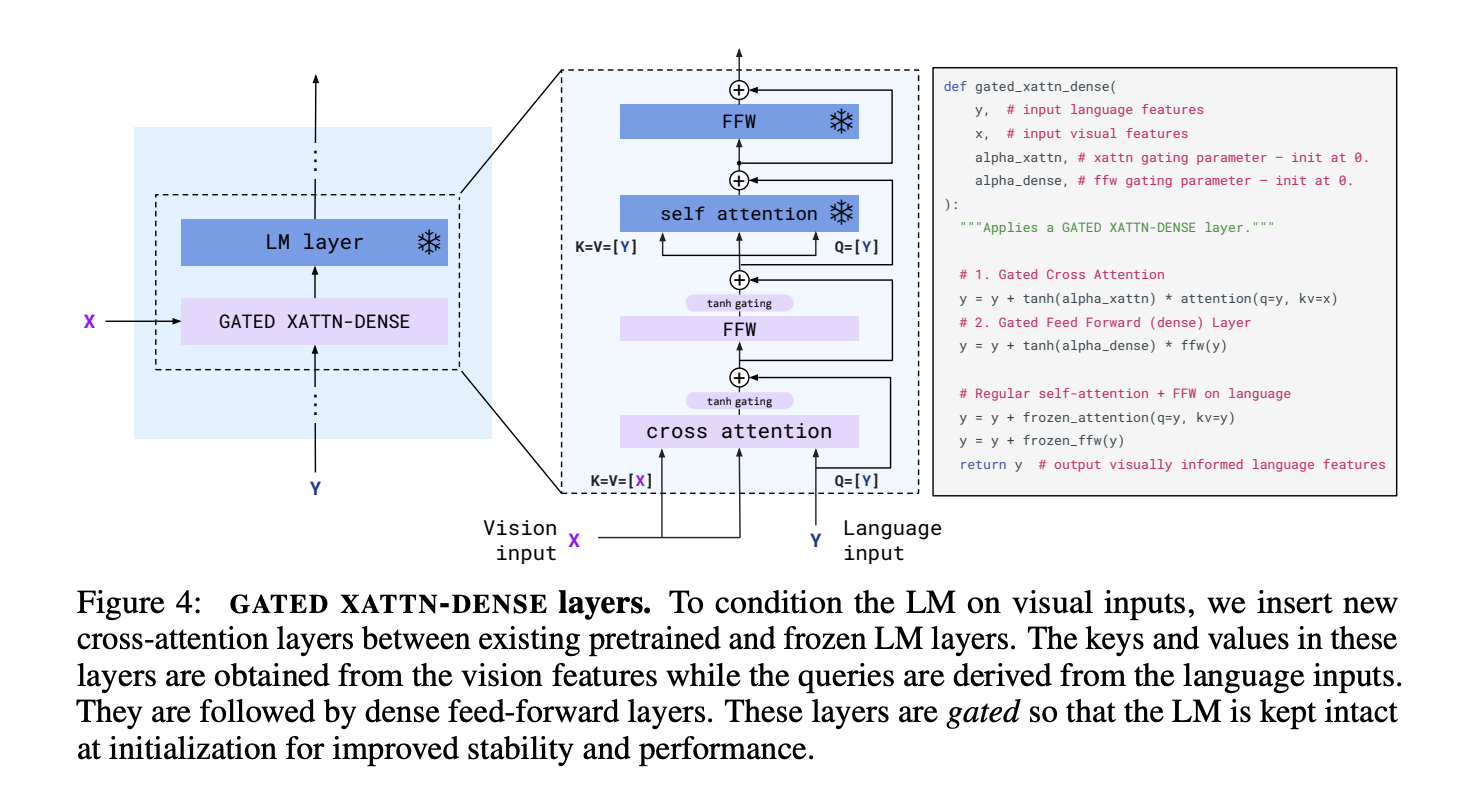
GATED XATTN-DENSE layers
GATED XATTN-DENSE layers are inserted between existing and frozen LM layers to allow the language model to attend more efficiently to the visual tokens when generating text tokens. Without these layers, Flamingo authors noted a drop of 4.2% in the overall score.
Loss function
Flamingo computes the likelihood of text \(y\) conditioned on the interleaved images and videos \(x\).
\[p(y|x) = \prod_{l=1}^N p(y_l|y_{<l}, x_{\leq l})\]The training loss function was a weighted sum of expected negative log-likelihoods of generated text across all 4 datasets, with \(\lambda_m\) being the training weight of dataset \(m\).
\[\sum_{m=1}^M \lambda_m E_{(x, y)\sim D_m} [ -\sum_{l=1}^L \log p(y|x)]\]Training
While the Chinchilla LM layers are finetuned and frozen, the additional components are trained from scratch, using all 4 Flamingo datasets, with different weights. Finding the right per-dataset weights was key to performance. The weight for each dataset is in the Training weight column in the dataset table above.
VTP’s weight is much smaller than other datasets (0.03 compared to 0.2 and 1), so its contribution to the training should be minimal. However, the authors noted that removing this dataset negatively affects performance on all video tasks.
While Flamingo isn’t open-sourced, there are many open-source replications of Flamingo.
- IDEFICS (HuggingFace)
- mlfoundations/open_flamingo
TL;DR: CLIP vs. Flamingo
Part 3. Research Directions for LMMs
CLIP is 3 years old and Flamingo is almost 2. While their architectures serve as a good foundation for us to understand how LMMs are built, there have been many new progresses in the space.
Here are a few directions that I’m excited about. This is far from an exhaustive list, both because this post has been long and because I’m still learning about the space too. If you have any pointers or suggestions, please let me know!
Incorporating more data modalities
Today, most multimodal systems work with text and images. It’s only a matter of time before we need systems that can incorporate other modalities such as videos, music, and 3D. Wouldn’t it be amazing to have one shared embedding space for ALL data modalities?
Examples of works in this space:
- ULIP: Learning a Unified Representation of Language, Images, and Point Clouds for 3D Understanding (Xue et al., Dec 2022)
- ImageBind: One Embedding Space To Bind Them All (Girdhar et al., May 2023)
- NExT-GPT: Any-to-Any Multimodal Large Language Model (Wu et al., Sep 2023)
- Jeff Dean’s ambitious Pathways project (2021): its vision is to “enable multimodal models that encompass vision, auditory, and language understanding simultaneously.”

Multimodal systems for instruction-following
Flamingo was trained for completion, but not for dialogue or for following instructions. (If you’re not familiar with completion vs. dialogue, check out my post on RLHF). Many people are working on building LMMs that can follow instructions and have conversations, such as:
- MultiInstruct: Improving Multi-Modal Zero-Shot Learning via Instruction Tuning (Xu et al., Dec 2022)
- LLaVA: Visual Instruction Tuning (Liu et al., Apr 28, 2023)
- InstructBLIP: Towards General-purpose Vision-Language Models with Instruction Tuning (Salesforce, May 11, 2023)
- LaVIN: Cheap and Quick: Efficient Vision-Language Instruction Tuning for Large Language Models (Luo et al., May 24, 2023)

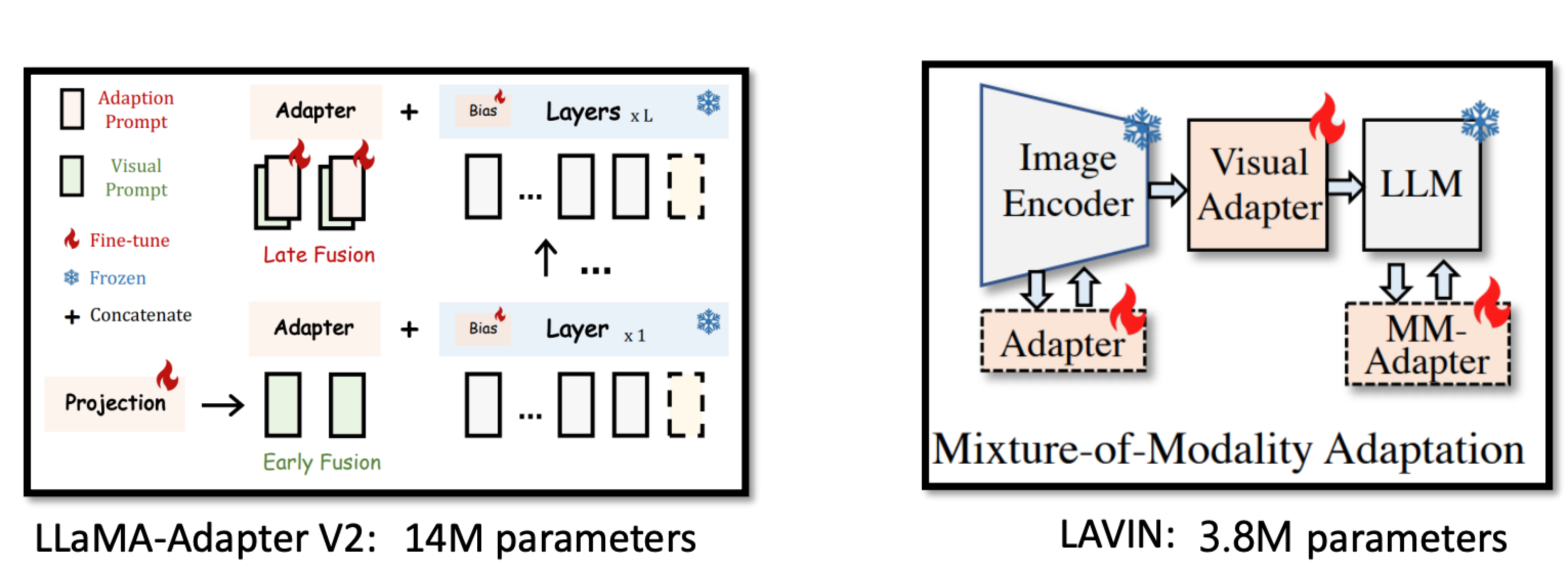
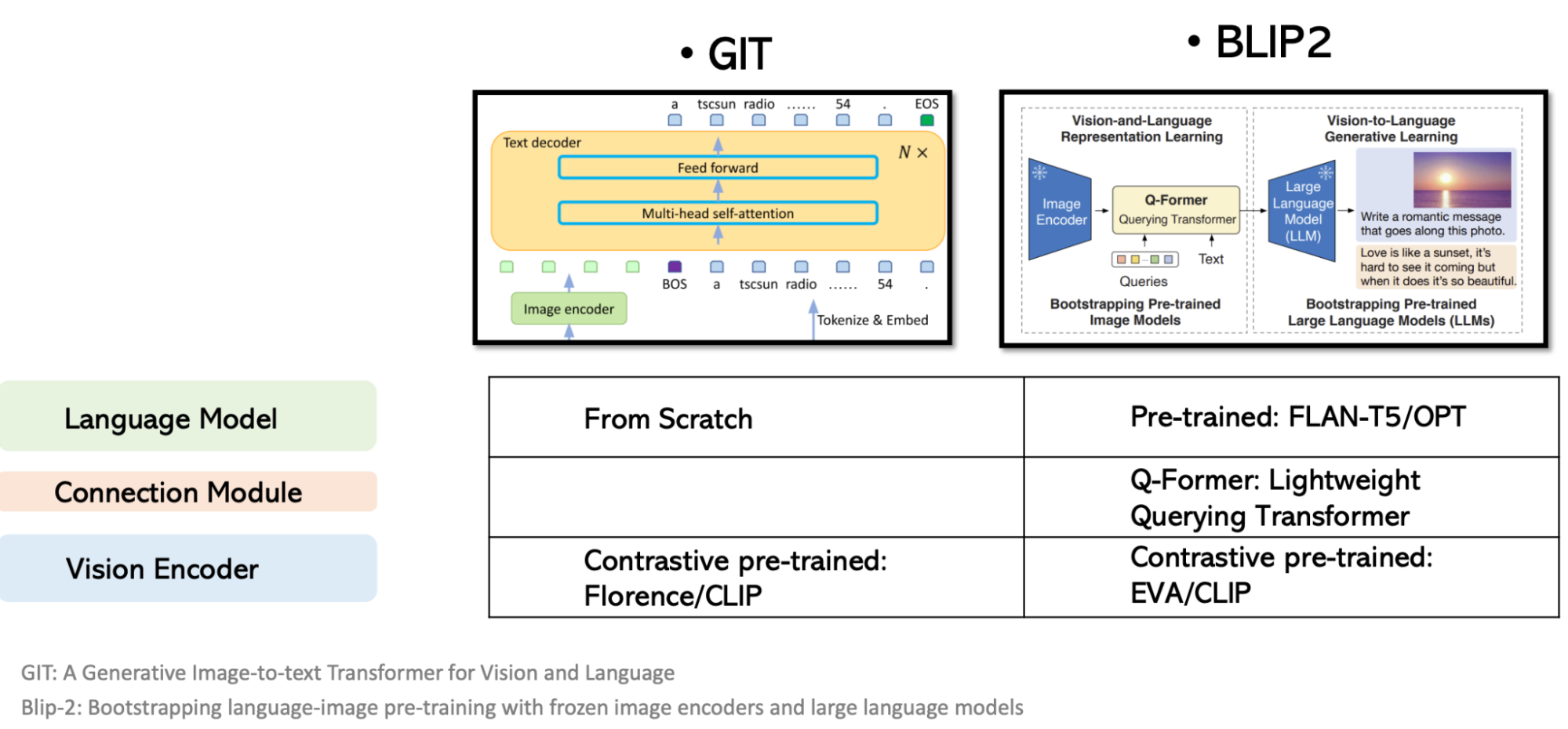
Adapters for more efficient multimodal training
While Flamingo used 9 pretrained and frozen layers from Chinchilla, it had to pretrain its vision encoder, Perceiver Resampler, and GATED XATTN-DENSE layers from scratch. These train-from-scratch modules could be compute-intensive. Many works focus on more efficient ways to bootstrap multimodal systems using less training from scratch.
Some works are quite promising. BLIP-2, for example, outperformed Flamingo-80B by 8.7% on zero-shot VQA-v2 with 54x fewer trainable parameters.
Works in this space include:
- BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models
- [LAVIN] Cheap and Quick: Efficient Vision-Language Instruction Tuning for Large Language Models
- LLaMA-Adapter V2: Parameter-Efficient Visual Instruction Model
The two images below are from Chunyuan Li’s Large Multimodal Models tutorial at CVPR 2023, which is, btw, an excellent tutorial.
Generating multimodal outputs
While models that can process multimodal inputs are becoming the norm, multimodal output is still lagging. Many use cases require multimodal outputs. For example, if we ask ChatGPT to explain RLHF, an effective explanation might require graphs, equations, and even simple animations.
To generate multimodal outputs, a model would first need to generate a shared intermediate output. One key question is what the intermediate output would look like.
One option for intermediate output is text, which will then be used to generate/synthesize other actions.
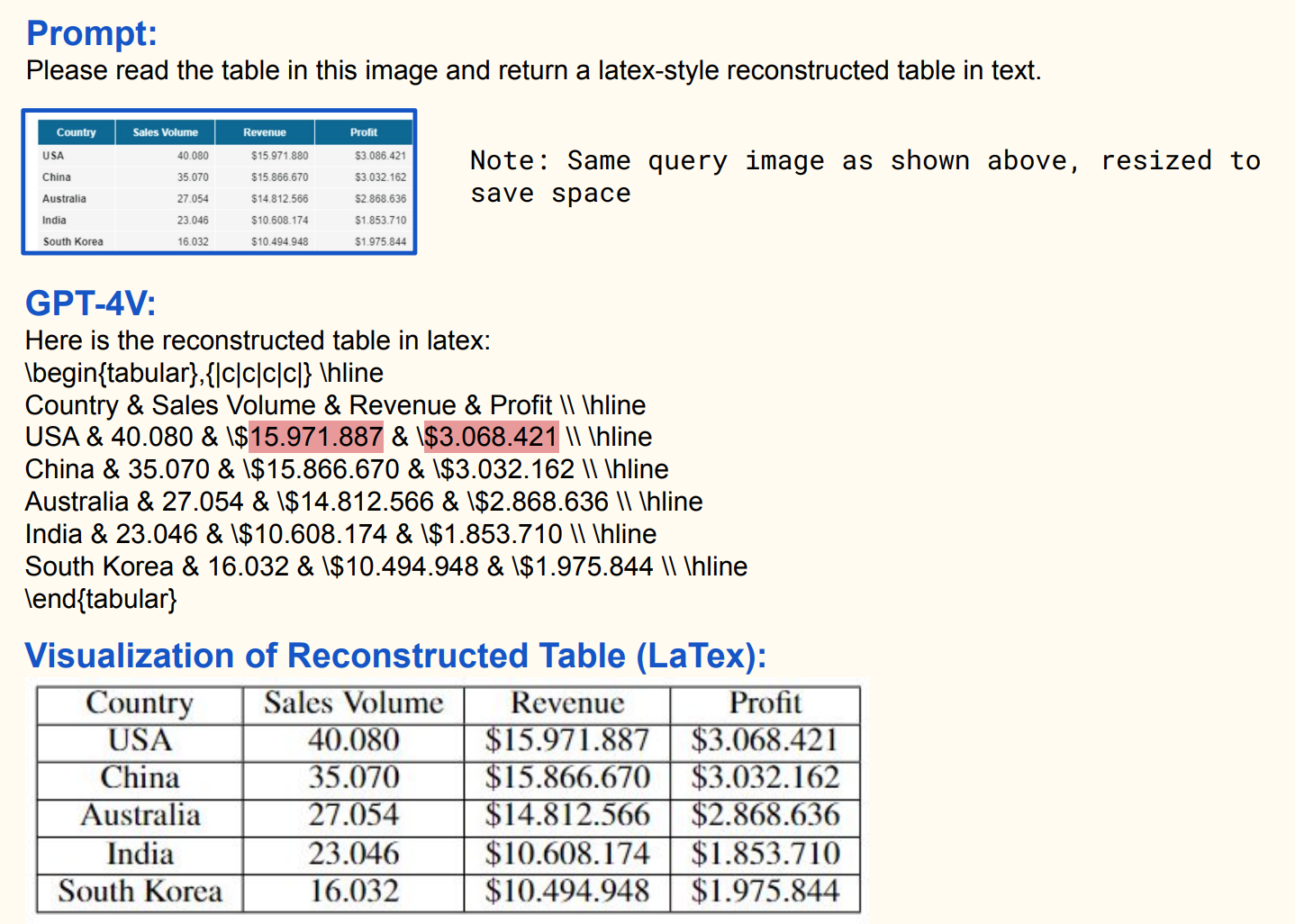
For example, CM3 (Aghajanyan et al., 2022) outputs HTML markup which can be compiled into webpages that contain not only text but also formattings, links, and images. GPT-4V generates Latex code, which can then be reconstructed as data tables.

Another option for intermediate output would be multimodal tokens. This is the option that Caiming Xiong, whose team at Salesforce has done a lot of awesome work on multimodality, told me. Each token will have a tag to denote whether it’s a text token or an image token. Image tokens will then be input into an image model like Diffusion to generate images. Text tokens will then be input into a language model.
Generating Images with Multimodal Language Models (Koh et al., Jun 2023) is an awesome paper that shows how LMMs can generate and retrieve images together with generating texts. See below.
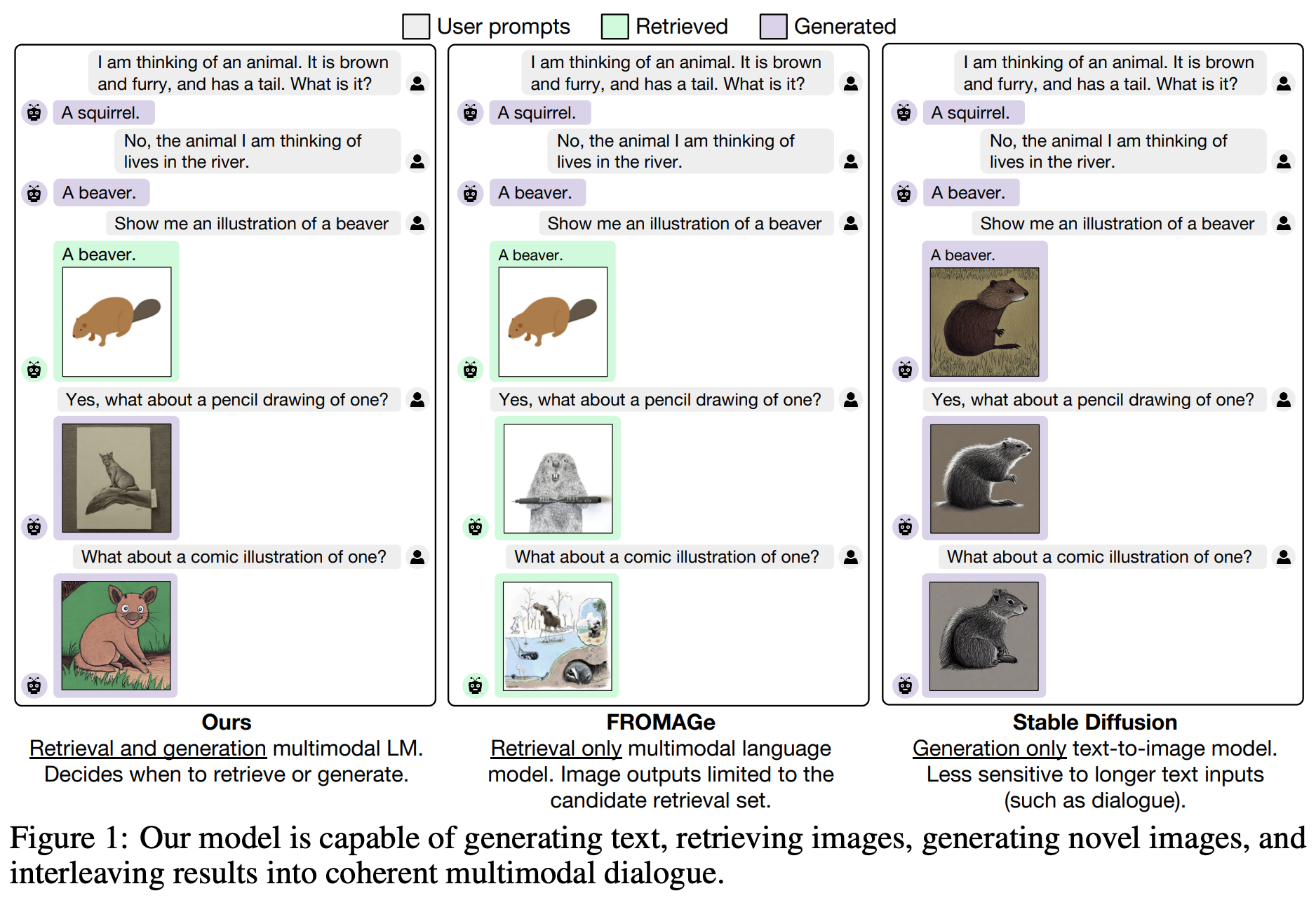
Conclusion
It’s been a lot of fun going over so many multimodal papers as well as talking to people doing awesome work and trying to summarize the key patterns in one blog post. There’s so much about multimodality that I’m sure there are many things that I’ve missed, but I hope that this post provides the core patterns that will help you develop multimodal systems and apply them to your work.
As you see in part 3 of this post, we’re still in the early days of multimodal systems (so early that a friend told me he’s not sure if the LMM abbreviation would catch on). Yes, in most of my conversations, there’s little doubt that multimodal systems in general, and LMMs in particular, will be even more impactful than large language models. However, keep in mind that LMMs do not make LLMs obsolete. As LMMs extend upon LLMs, the performance of an LMM relies on the performance of its base LLM. Many labs that work on multimodal systems work on LLMs in parallel.
Early reviewers
I’d like to thank the amazing early reviewers who gave me plenty of pointers and suggestions to make this post better: Han-chung Lee, Sam Reiswig, and Luke Metz.
Resources
Models
An incomplete list of multimodal systems by time to give you a sense of how fast the space is moving!
- Microsoft COCO Captions: Data Collection and Evaluation Server (Apr 2015)
- VQA: Visual Question Answering (May 2015)
- VideoBERT: A Joint Model for Video and Language Representation Learning (Google, Apr 3, 2019)
- LXMERT: Learning Cross-Modality Encoder Representations from Transformers (UNC Chapel Hill, Aug 20, 2019)
- [CLIP] Learning Transferable Visual Models From Natural Language Supervision (OpenAI, 2021)
- Unifying Vision-and-Language Tasks via Text Generation (UNC Chapel Hill, May 2021)
- BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation (Salesforce, Jan 28, 2022)
- Flamingo: a Visual Language Model for Few-Shot Learning (DeepMind, April 29, 2022)
- GIT: A Generative Image-to-text Transformer for Vision and Language (Microsoft, May 2, 2022)
- MultiInstruct: Improving Multi-Modal Zero-Shot Learning via Instruction Tuning (Xu et al., Dec 2022)
- BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models (Salesforce, Jan 30, 2023)
- Cross-Modal Fine-Tuning: Align then Refine (Shen et al., Feb 11, 2023)
- KOSMOS-1: Language Is Not All You Need: Aligning Perception with Language Models (Microsoft, Feb 27, 2023)
- PaLM-E: An Embodied Multimodal Language Model (Google, Mar 10, 2023)
- LLaMA-Adapter: Efficient Fine-tuning of Language Models with Zero-init Attention (Zhang et al., Mar 28, 2023)
- mPLUG-Owl: Modularization Empowers Large Language Models with Multimodality (Ye et al., Apr 2, 2023)
- LLaMA-Adapter V2: Parameter-Efficient Visual Instruction Model (Gao et al., Apr 28, 2023)
- LLaVA: Visual Instruction Tuning (Liu et al., Apr 28, 2023)
- X-LLM: Bootstrapping Advanced Large Language Models by Treating Multi-Modalities as Foreign Languages (Chen et al., May 7, 2023)
- InstructBLIP: Towards General-purpose Vision-Language Models with Instruction Tuning (Salesforce, May 11, 2023)
- Towards Expert-Level Medical Question Answering with Large Language Models (Singhal et al., May 16, 2023)
- Cheap and Quick: Efficient Vision-Language Instruction Tuning for Large Language Models (Luo et al., May 24, 2023)
- Shikra: Unleashing Multimodal LLM’s Referential Dialogue Magic (SenseTime, Jun 3, 2023)
- Macaw-LLM: Multi-Modal Language Modeling with Image, Audio, Video, and Text Integration (Tencent, Jun 15, 2023)
Other resources
- [CVPR2023 Tutorial Talk] Large Multimodal Models: Towards Building and Surpassing Multimodal GPT-4
- Slides: Large Multimodal Models
- [CMU course] 11-777 MMML
- [Open source] Salesforce’s LAVIS