A friendly introduction to machine learning compilers and optimizers
[Twitter thread, Hacker News discussion]
I have a confession to make. I cried during the compiler class in college. I became a machine learning engineer so that I wouldn’t have to worry about compilers.
However, as I learned more about bringing ML models into production, the topic of compilers kept coming up. In many use cases, especially when running an ML model on the edge, the model’s success still depends on the hardware it runs on, which makes it important for people working with ML models in production to understand how their models are compiled and optimized to run on different hardware accelerators.
Ideally, the compiler would be invisible and everything would “just work”. However, we are still many years away from that. As more and more companies want to bring ML to the edge, and more and more hardware is being developed for ML models, more and more compilers are being developed to bridge the gap between ML models and hardware accelerators—MLIR dialects, TVM, XLA, PyTorch Glow, cuDNN, etc.. According to Soumith Chintala, creator of PyTorch, as the ML adoption matures, companies will compete on who can compile and optimize their models better.
Understanding how compilers work can help you choose the right compiler to bring your models to your hardware of choice as well as diagnose performance issues and speed up your models.

This post is a (hopefully) friendly, tearless introduction to ML compilers. It starts with the rise of edge computing, which, I believe, brought compilers out of the realm of system engineers into the realm of general ML practitioners. If you’re already convinced of ML of the edge, feel free to skip this part.
The next section is about the two major problems with deploying ML models on the edge: compatibility and performance, how compilers can address these problems, and how compilers work. It ends with a few resources on how to significantly speed up your ML models with just a few lines of code.
1. Cloud computing vs. Edge computing
Imagine you’ve trained an incredible ML model whose accuracy outperforms your wildest expectations. You’re excited to deploy this model so that it’s accessible to users.
The easiest way is to package your model up and deploy it via a managed cloud service such as AWS or GCP, and this is how many companies deploy when they get started in ML. Cloud services have done an incredible job to make it easy for companies to bring ML models into production.
However, there are many downsides to cloud deployment. The first is the cost. ML models can be compute-intensive, and compute is expensive. Even back in 2018, big companies like Pinterest, Infor, Intuit, etc. were already spending hundreds of millions of dollars in cloud bills every year [1, 2]. That number for small and medium companies can be between $50K - 2M a year. A mistake in handling cloud services can cause startups to go bankrupt [1, 2].
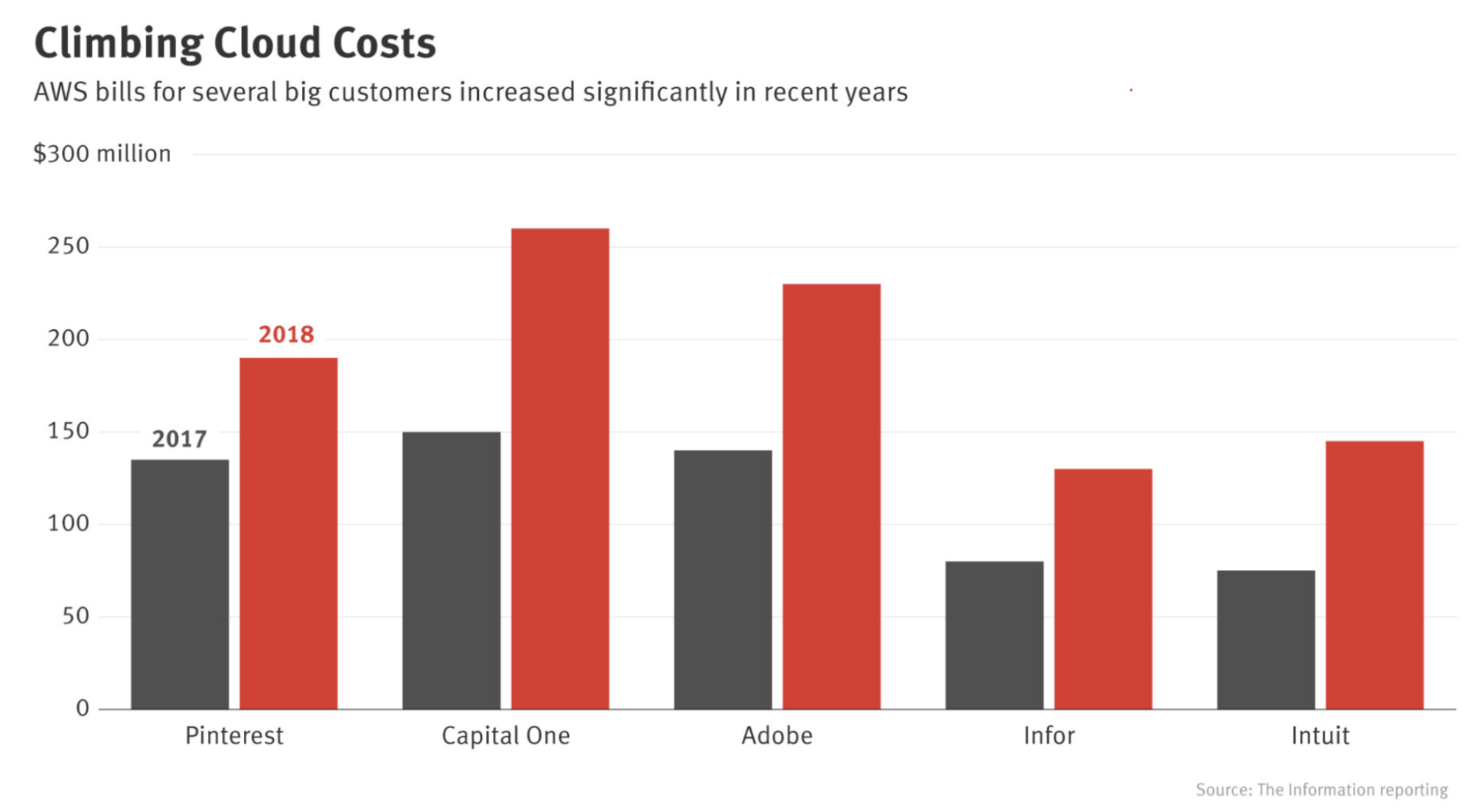
As their cloud bills climb, more and more companies are looking for ways to push their computations to consumer devices (edge devices). The more computation is done on the edge, the less is required on the cloud, and the less they’ll have to pay for servers.
Other than help with controlling costs, there are many properties that make edge computing appealing. The first is that it allows your applications to run where cloud computing cannot. When your models are on public clouds, they rely on stable Internet connections to send data to the cloud and back. Edge computing allows your models to work in situations where there are no Internet connections or where the connections are unreliable, such as in rural areas or developing countries.
Second, when your models are already on consumers’ devices, you can worry less about network latency. Requiring data transfer over the network (send data to the model on the cloud to make predictions then send predictions back to the users) might make some use cases impossible. In many cases, network latency is a bigger bottleneck than inference latency. For example, you might be able to reduce the inference latency of ResNet50 from 30ms to 20ms, but the network latency can go up to seconds, depending on where you are.
Putting your models on the edge is also appealing when handling sensitive user data. ML on the cloud means that your systems might have to send user data over networks, making it susceptible to being intercepted. Cloud computing also often means storing data of many users in the same place, which means a breach can affect many people. Nearly 80% of companies experienced a cloud data breach in past 18 months, reported the Security magazine in 2020. Edge computing makes it easier to comply with regulations (e.g. GDPR) about how user data can be transferred or stored.
2. Compiling: compatibility
Because of the many benefits that edge computing has over cloud computing, companies are in a race to develop edge devices optimized for different ML use cases. Established companies including Google, Apple, Tesla have all announced their plans to make their own chips. Meanwhile, ML hardware startups have raised billions of dollars to develop better AI chips.
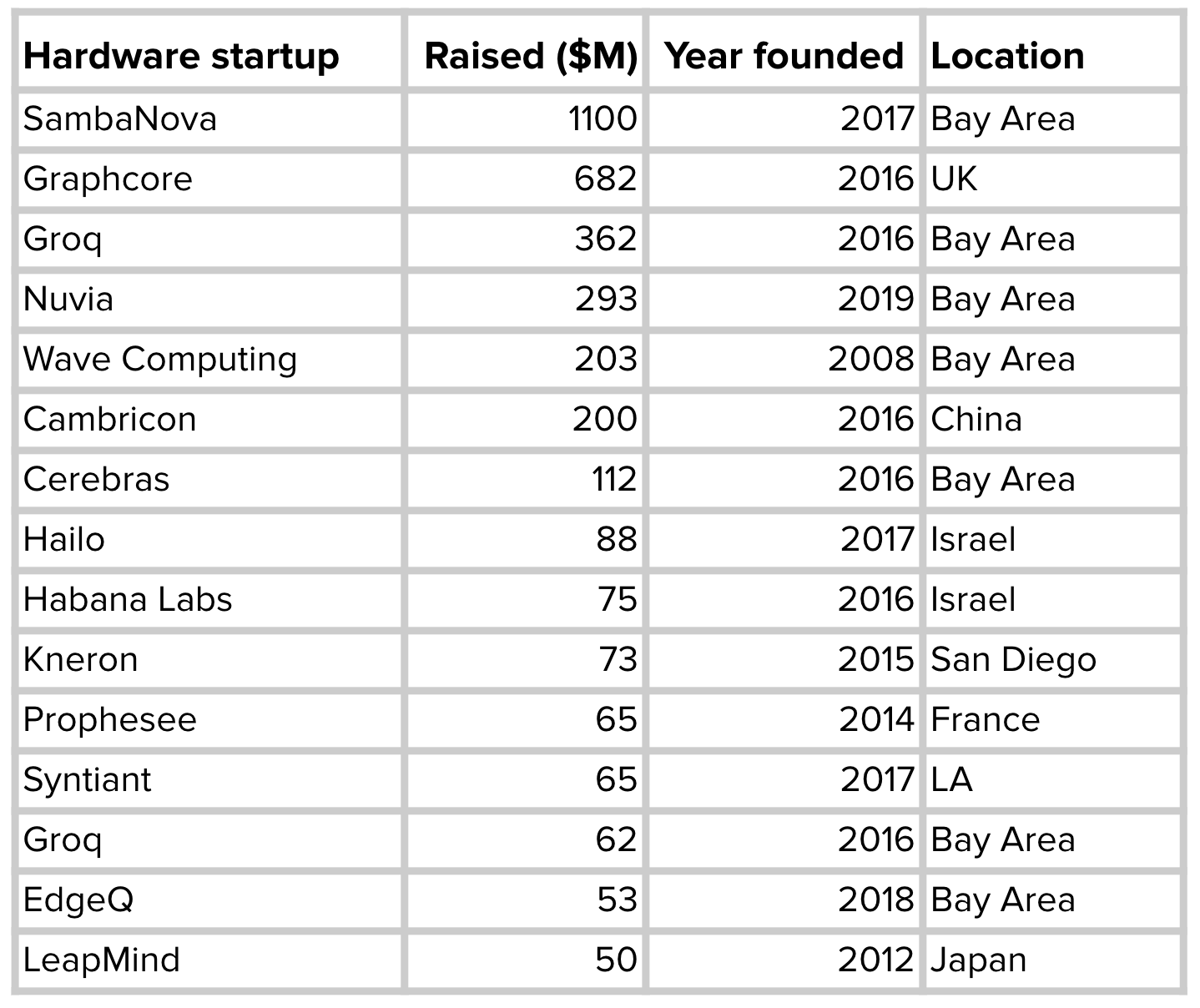
With so many new offerings for hardware to run ML models on, one question arises: how do we make a model built with an arbitrary framework run on arbitrary hardware?
For a framework to run on a piece of hardware, it has to be supported by the hardware vendor. For example, even though TPUs were released publicly in Feb 2018, it wasn’t until Sep 2020 that PyTorch was supported on TPUs. Before then, if you wanted to use a TPU, you’d have to use TensorFlow or JAX.
Providing support for a framework on a type of hardware (platform) is time-consuming and engineering intensive. Mapping from ML workloads to hardware requires understanding and being able to take advantage of the hardware’s infrastructure. However, a fundamental challenge is that different hardware types have different memory layouts and compute primitives, as shown in this illustration below by Chen et al..
For example, the compute primitive of CPUs used to be a number (scalar), the compute primitive of GPUs used to be a one-dimensional vector, whereas the compute primitive of TPUs is a two-dimensional vector (tensor). However, many CPUs these days have vector instructions and some GPUs have tensor cores, which are 2-dimensional. Performing a convolution operator on a batch of 256 images x 3 channels x 224 W x 224 H will be very different with 1-dimensional vectors compared to 2-dimensional vectors. Similarly, you’d need to take into account different L1, L2, and L3 layouts and buffer sizes to use them efficiently.
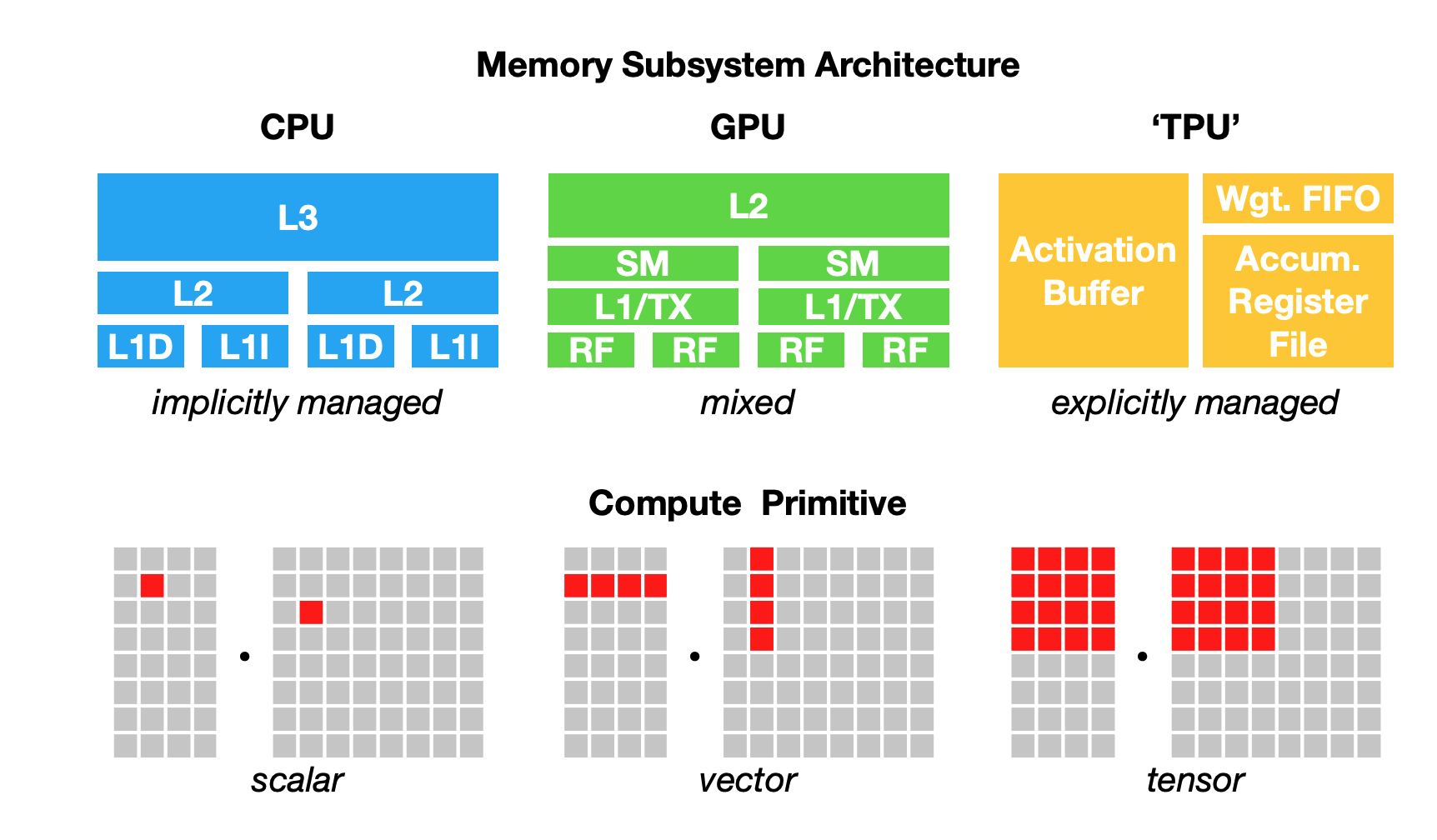
Image by Chen et al., 2018.
Because of this, framework developers tend to focus on providing support to only a handful of server-class hardware (e.g. GPUs), and hardware vendors tend to offer their own kernel libraries for a narrow range of frameworks (e.g. Intel has OpenVino that supports only Caffe, TensorFlow, MXNet, Kaldi, and ONNX. NVIDIA has CUDA and cuDNN). Deploying ML models to new hardware – such as mobile phones, embedded devices, FPGAs, and ASICs – requires significant manual effort.

Replace ? with compiler names.
Intermediate representation (IR)
Instead of targeting new compilers and libraries for every new hardware type and device, what if we create a middle man to bridge frameworks and platforms? Framework developers will no longer have to support every type of hardware, only need to translate their framework code into this middle man. Hardware vendors can then support one intermediate framework instead of supporting many?
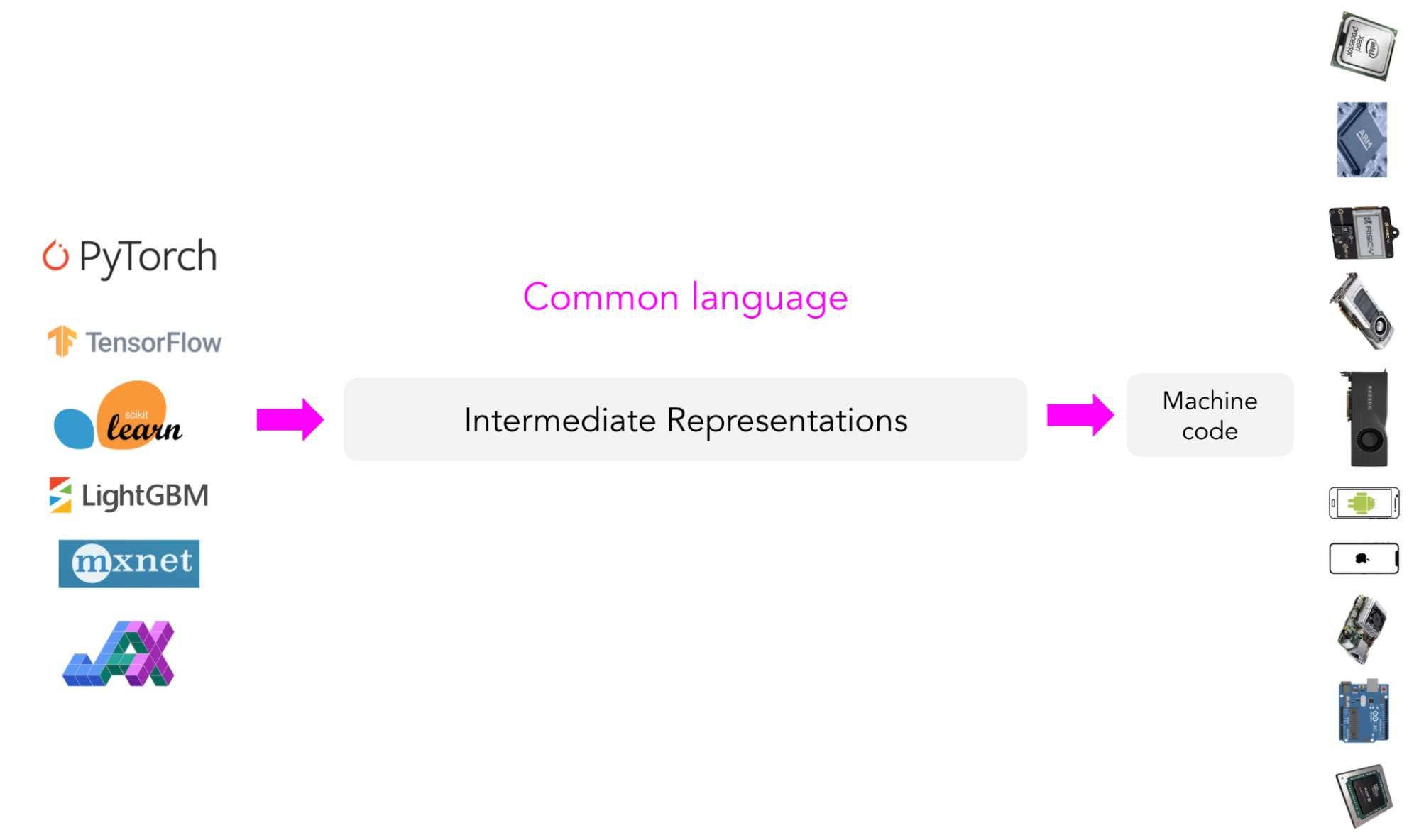
This type of “middle man” is called an intermediate representation (IR). IRs lie at the core of how compilers work. From the original code for your models, compilers generate a series of high- and low-level intermediate representations before generating hardware-native code to run your models on a certain platform.
To generate machine-native code from an IR, compilers typically leverage a code generator, also known as a codegen. The most popular codegen used by ML compilers is LLVM, developed by Vikram Adve and Chris Lattner (who changed the our conception of systems engineering with the creation of LLVM). TensorFlow XLA, NVIDIA CUDA compiler (NVCC), MLIR (a meta-compiler that is used to build other compilers), and TVM all use LLVM.
This process is also called “lowering”, as in you “lower” your high-level framework code into low-level hardware-native code. It’s not “translating” because there’s no one-to-one mapping between them.
High-level IRs are usually computation graphs of your ML models. For those familiar with TensorFlow, the computation graphs here are similar to the computation graphs you have encountered in TensorFlow 1.0, before TensorFlow switched to eager execution. In TensorFlow 1.0, TensorFlow first built the computation graph of your model before running it. This computation graph allows TensorFlow to understand your model to optimize its runtime.
High-level IRs are generally hardware-agnostic (doesn’t care what hardware it’ll be run on), while low-level IRs are generally framework-agnostic (doesn’t care what framework the model was built with).
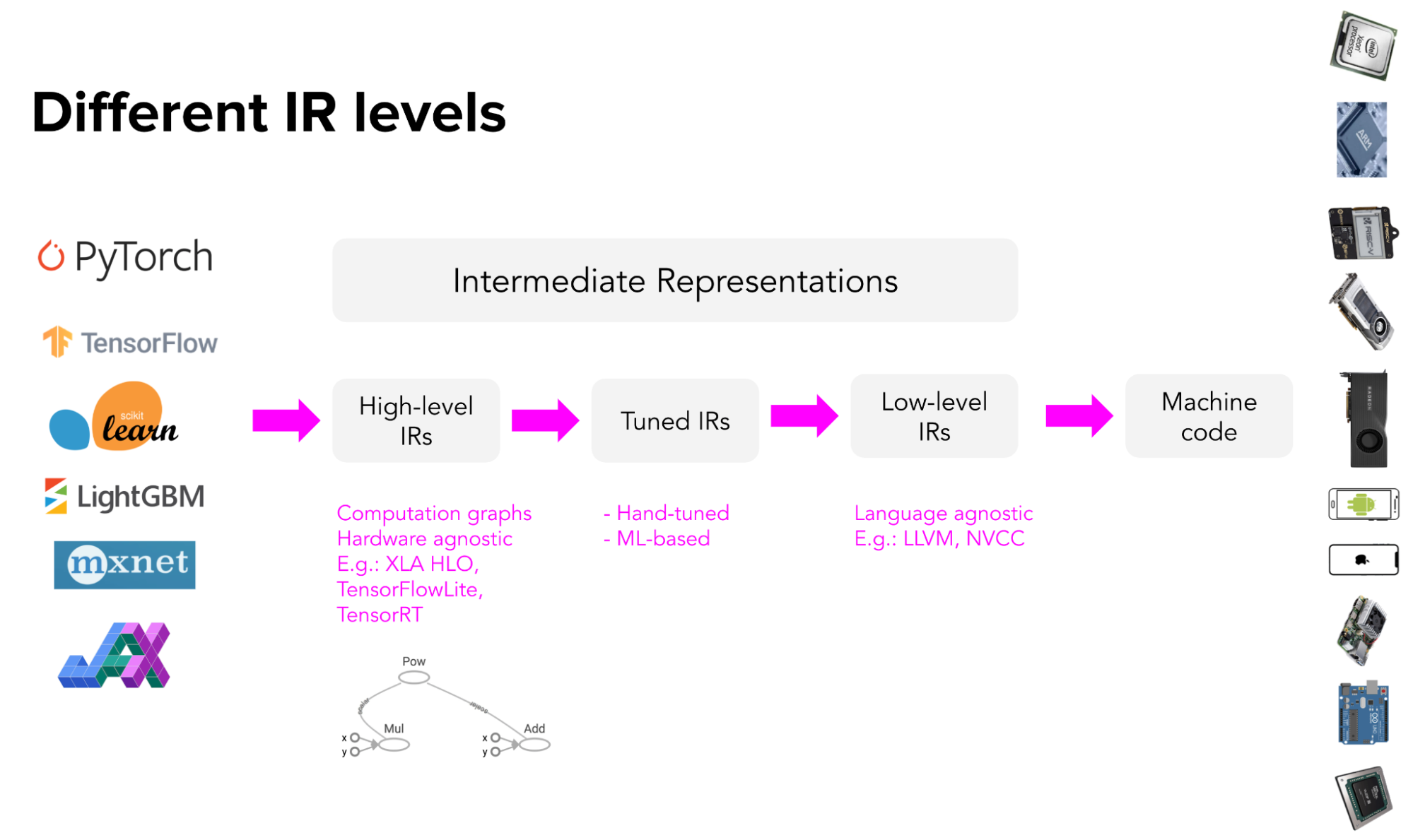
We'll go over Tuned IRs in the next section.
3. Optimizing: performance
After you’ve “lowered” your code to run your models into the hardware of your choice, an issue you might run into is performance. Codegen is very good at lowering an IR to machine code, but depending on the target hardware backend, the generated machine code may not perform as well as it could. The generated code may not take advantage of data locality and hardware caches, or it may not leverage advanced features such as vector or parallel operations that could speed code up.
A typical ML workflow consists of many frameworks and libraries. For example, you might use pandas/dask/ray to extract features from your data. You might use NumPy to perform vectorization. You might use a tree model like LightGBM to generate features, then make predictions using an ensemble of models built with various frameworks like sklearn, TensorFlow, or transformers.
Even though individual functions in these frameworks might be optimized, there’s little to no optimization across frameworks. A naive way of moving data across these functions for computation can cause an order of magnitude slowdown in the whole workflow. A study by researchers at Stanford DAWN lab found that typical ML workloads using NumPy, Pandas and TensorFlow run 23 times slower in one thread compared to hand-optimized code (Palkar et al., ‘18).
What usually happens in production is that data scientists/ML engineers pip install the packages required for their jobs. Things seem to be working fine in the development environment so they deploy their models to the production environment. When they run into performance issues in production, their companies will often hire optimization engineers to optimize their models for the hardware they run on.


Optimization engineers are hard to come by and expensive to hire because they need to have expertise in both ML and hardware architectures. Optimizing compilers (compilers that also optimize your code) is an alternative solution as they can automate the process of optimizing models. In the process of lowering ML model code into machine code, compilers can look at the computation graph of your ML model and the operators it consists of — convolution, loops, cross-entropy — and find a way to speed it up.
To summarize what you’ve covered so far, compilers bridge ML models and the hardware they run on. An optimizing compiler consists of two components: lowering and optimizing. These two components aren’t necessarily separate. Optimizing can occur at all stages, from high-level IRs to low-level IRs.
- Lowering: compilers generate hardware-native code for your models so that your models can run on certain hardware.
- Optimizing: compilers optimize your models to run on that hardware.
4. How to optimize your ML models
There are two ways to optimize your ML models: locally and globally. Locally is when you optimize an operator or a set of operators of your model. Globally is when you optimize the entire computation graph end-to-end.
There are standard local optimization techniques that are known to speed up your model, most of them making things run in parallel or reducing memory access on chips. Here are four of the common techniques.
- vectorization: given a loop or a nested loop, and instead of executing it one item at a time, use hardware primitives to operate on multiple elements that are contiguous in memory.
- parallelization: given an input array (or n-dimensional array), divide it into different, independent work chunks, and do the operation on each chunk individually.
- loop tiling: change the data accessing order in a loop to leverage hardware’s memory layout and cache. This kind of optimization is hardware dependent. A good access pattern on CPUs is not a good access pattern on GPUs. See visualization below by Colfax Research.
- operator fusion: fuse multiple operators into one to avoid redundant memory access. For example, two operations on the same array require two loops over that array. In a fused case, it’s just a single loop. See an example below by Matthias Boehm.


According to Shoumik Palkar, the creator of Weld (another compiler), these standard local optimization techniques can be expected to give ~3x speed up. Of course, this estimate is highly context-dependent.
To obtain a much bigger speedup, you’d need to leverage higher-level structures of your computation graph. For example, given a convolution neural network with the computation graph can be fused vertically or horizontally to reduce memory access and speed up the model. See visualization below by NVIDIA’s TensorRT team.
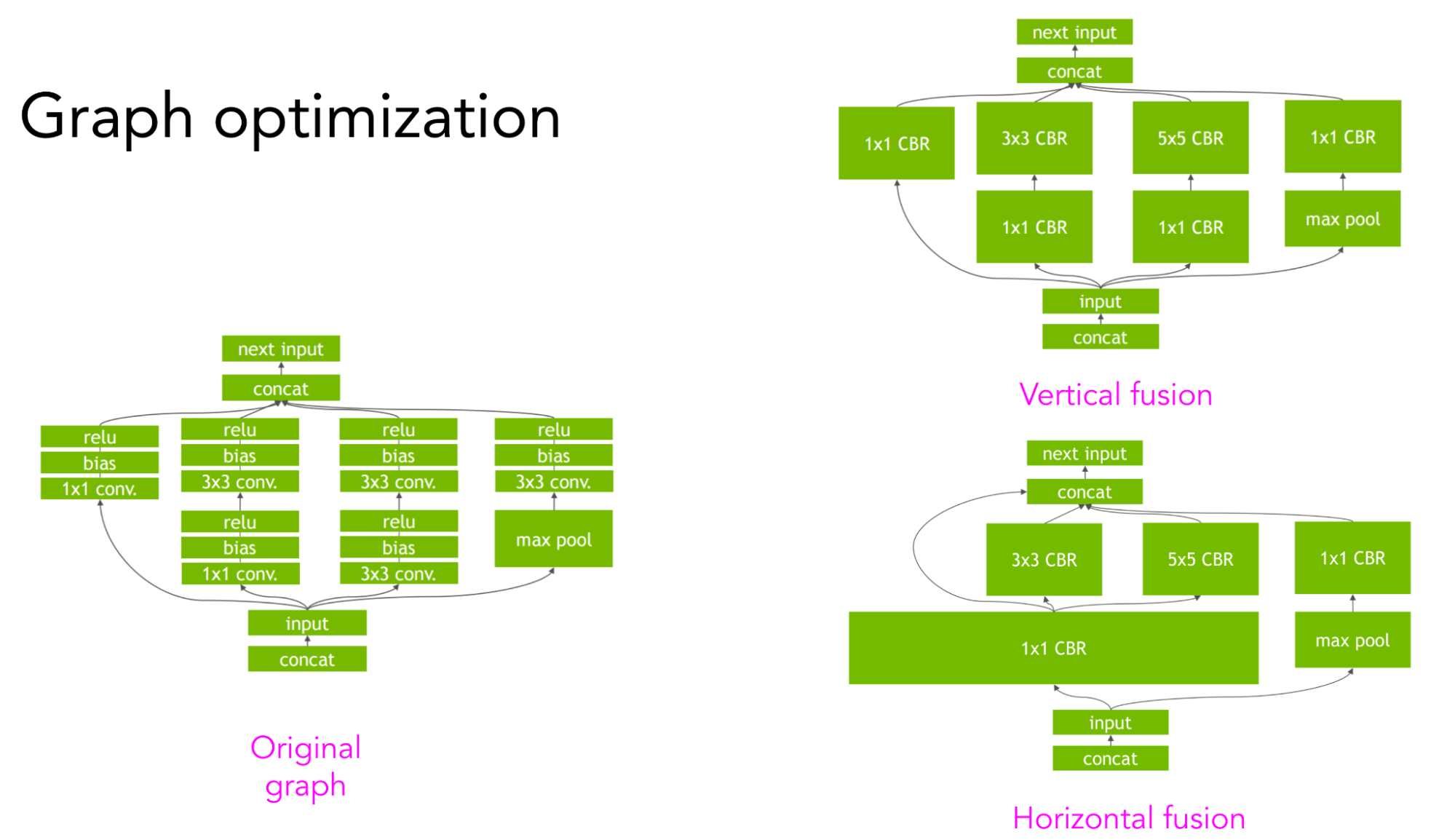
Illustration by TensorRT.
5. Hand-designed vs. ML-based compilers
Hand-designed rules
As hinted by the previous section with the vertical and horizontal fusion of a convolution NN, there are many possible ways to execute a given computation graph. For example, given 3 operators A, B, and C, you can either fuse A with B, fuse B with C, or fuse A, B, and C altogether.
Traditionally, framework and hardware vendors hire optimization engineers who, based on their experience, come up with heuristics on how to best execute the computation graph of a model. For example, NVIDIA might have an engineer or a team of engineers who focuses exclusively on how to make ResNet-50 run really fast on their DGX A100 server. (This is also why you shouldn’t read too much into MLPerf’s results. A popular model running really fast on a type of hardware doesn’t mean an arbitrary model will run really fast on that hardware. It might just be that this model is over-optimized).
There are a couple of drawbacks to hand-designed rules. The first is that they are non-optimal. There’s no guarantee that the heuristics an engineer comes up with are the best possible solution.
Second, they are non-adaptive. Repeating the process on a new framework or a new hardware architecture requires an enormous amount of effort.
This is complicated by the fact model optimization is dependent on the set of operators that makes up its computation graph. Optimizing a convolution neural network is different from optimizing a recurrent neural network, which is different from optimizing a transformer. NVIDIA and Google focus on optimizing popular models like ResNet and BERT on their hardware. But what if you, as an ML researcher, come up with a new model architecture? You might need to optimize it yourself to show that it’s fast first before it’s adopted and optimized by hardware vendors.
ML-based compilers
The goal is to find the fastest way out of all possible ways to execute a computation graph. What if we try all possible ways, record the time they need to run, then pick the best one?
The problem is that there are too many possible ways (paths) to explore (combinatorial!), and trying them all would prove to be infeasible. What if we use ML to:
- narrow down the search space so we don’t have to try out that many paths.
- predict how long a path will take so that we don’t have to wait for the entire computation graph to finish executing.
To estimate how much time a path through an entire computation graph will take to run turns out to be extremely difficult, as it requires making a lot of assumptions about that graph. What is possible with the current technology is to focus on a small part of the graph.
If you use PyTorch on GPUs, you might have seen torch.backends.cudnn.benchmark=True. When this is set to True, cuDNN autotune will be enabled. cuDNN autotune searches over a predetermined set of options to execute a convolution operator and then chooses the fastest way. cuDNN autotune is helpful if you run the same convnet shape every iteration. It will be slow the first time the convolution operator is run because cuDNN autotune takes time to run the search. But on subsequent runs, cuDNN will use the cached results of autotuning to choose the fastest configuration .
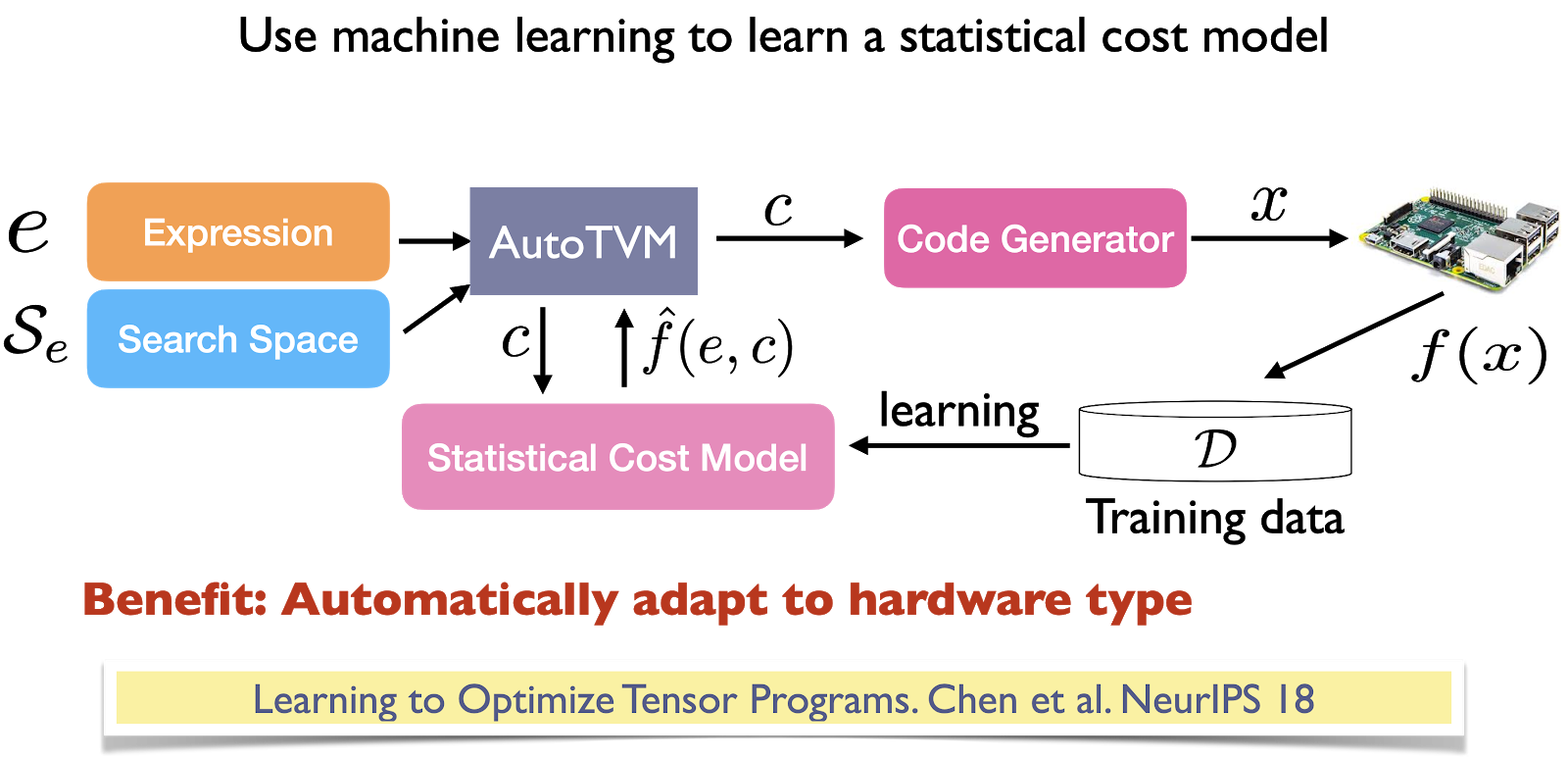
cuDNN autotune, despite its effectiveness, only works for convolution operators and, AFAIK, is only exposed for PyTorch and MXNet. A much more general solution is autoTVM, which is part of the open-source compiler stack TVM. autoTVM works with subgraphs instead of just an operator, so the search spaces it works with are much more complex. The way autoTVM works is quite complicated, but here is the gist:
- It first breaks your computation graph into subgraphs.
- It predicts how big each subgraph is.
- It allocates time to search for the best possible path for each subgraph.
- It stitches the best possible way to run each subgraph together to execute the entire graph.
autoTVM measures the actual time it takes to run each path it goes down, which gives it ground truth data to train a cost model to predict how long a future path will take. The pro of this approach is that because the model is trained using the data generated during runtime, it can adapt to any type of hardware it runs on. The con is that it takes more time for the cost model to start improving.
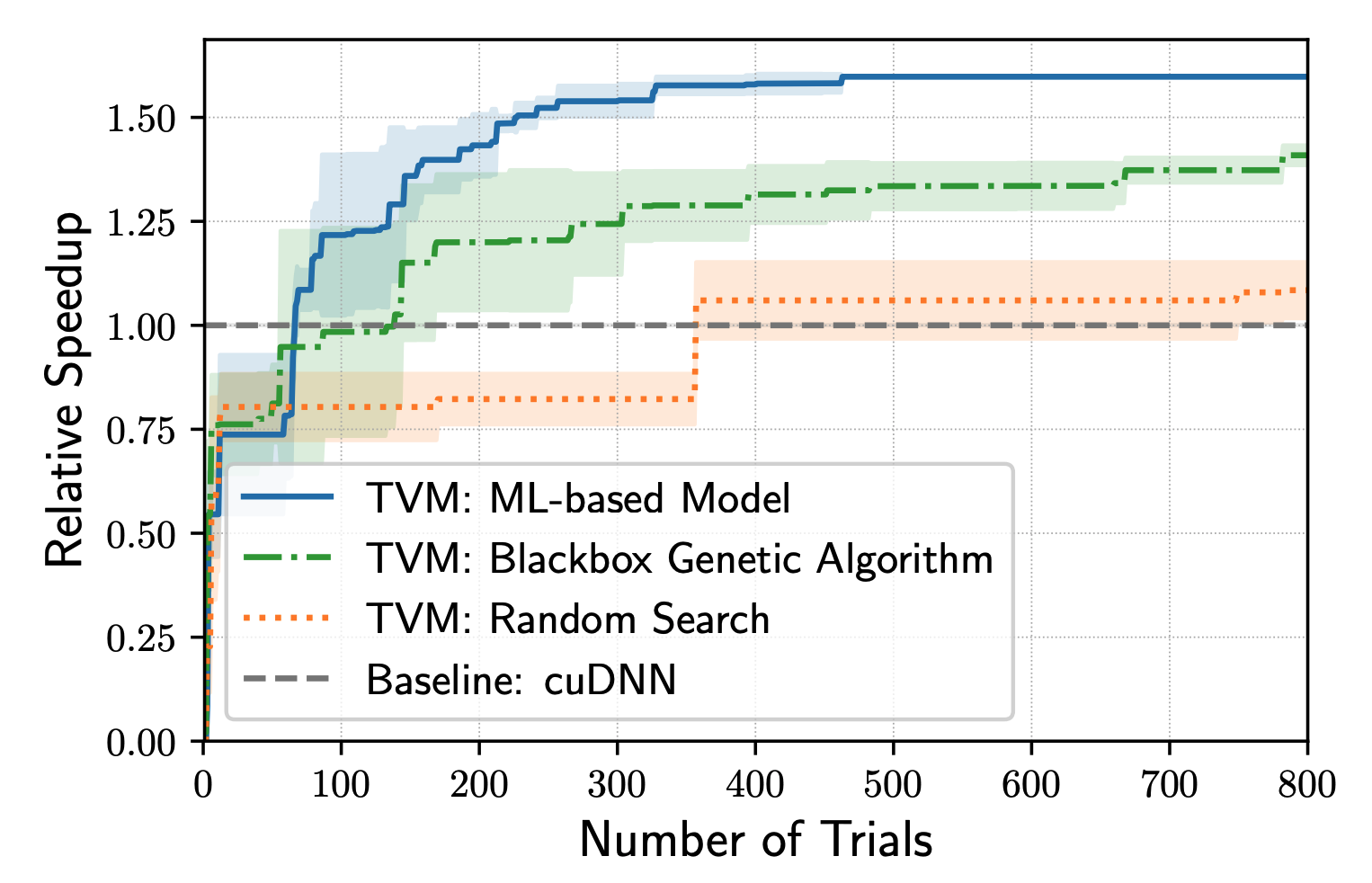
It takes ~70 trials for the ML-based TVM to outperform cuDNN.
Experiment by Chen et al.
Compilers like TVM are adaptive, flexible and can be especially useful when you want to try out new hardware. One example is when Apple released their M1 chips in Nov 2020. M1 is an ARM-based system on a chip, and ARM architectures are more or less well-understood. However, M1 still has a lot of novel components of its ARM implementation and requires significant optimization to make various ML models run fast on it. A month after the release, folks at OctoML showed that the optimization made by autoTVM is almost 30% faster than hand-designed optimization by Apple’s Core ML team. Of course, as M1 matures and hand-designed optimization becomes intensive, it will be hard for auto-optimization to beat hand-designed optimization. But it’s possible for systems engineers to leverage tools like autoTVM to speed up their optimization.
While the auto tuning results are impressive, they come with a catch: TVM can be slow. You go through all the possible paths and find the most optimized ones. This process can take hours, even days for complex ML models. However, it’s a one-time operation, and the results of your optimization search can be cached and used to both optimize existing models and provide a starting point for future tuning sessions. You optimize your model once for one hardware backend then run it on multiple devices of that same backend. This sort of optimization is ideal when you have a model ready for production, and target hardware to run inference on.
6. Different types of compilers
The most widely-used type of compiler is domain-specific compilers developed by major framework and hardware vendors targeting a specific combination of framework and hardware. Unsurprisingly, the most popular ones are developed by the biggest vendors.
- NVCC (NVIDIA CUDA Compiler): works only with CUDA. Closed-source.
- XLA (Accelerated Linear Algebra, Google): originally intended to speed up TensorFlow models, but has been adopted by JAX. Open-source as part of the TensorFlow repository.
- PyTorch Glow (Facebook): PyTorch has adopted XLA to enable PyTorch on TPUs, but for other hardware, it relies on PyTorch Glow. Open-source as part of the PyTorch repository.
Third-party compilers are, in general, very ambitious (e.g. you must be really confident to think that you can optimize for GPUs better than NVIDIA can). But third-party compilers are important as they help lower the overhead in making new frameworks, new hardware generations, new models performant, giving small players a chance to compete with established players who have their own compilers heavily tuned for their existing products.
The best third-party compiler I see is Apache TVM, which works with a wide range of frameworks (including TensorFlow, MXNet, PyTorch, Keras, CNTK) and a wide range of hardware backends (including CPUs, server GPUs, ARMs, x86, mobile GPUs, and FPGA-based accelerators).
Another project that I find exciting is MLIR, which was originally started at Google also by Chris Lattner (the creator of LLVM). However, it’s now under the LLVM organization. MLIR is not really a compiler but a meta compiler, infrastructure that allows you to build your own compiler. MLIR can run multiple IRs, including TVM’s IRs, as well as LLVM IR and TensorFlow graphs.
WebAssembly (WASM)
This is something that I’m so excited about that I needed to create a section for this. WASM is one of the most exciting technological trends I’ve seen in the last couple of years. It’s performant, easy to use, and has an ecosystem that is growing like wildfire [1, 2]. As of September 2021, it’s supported by 93% of devices worldwide.
We’ve been talking about how compilers can help us generate machine-native code for our models to run on certain hardware back-ends. What if we want to generate some code that can run on just any hardware backends?
Entered the good old browsers. If you can run your model in a browser, you can run your model on any device that supports browsers: Macbooks, Chromebooks, iPhones, Android phones, etc. You wouldn’t need to care what chips those devices use. If Apple decides to switch from Intel chips to ARM chips, it’s not your problem!
My students are slowly realizing that if they want to run their models in browsers, they can't avoid JavaScript 🤪 pic.twitter.com/N30UOhnpxM
— Chip Huyen (@chipro) February 19, 2021
WebAssembly is an open standard that allows you to run executable programs in browsers. After you’ve built your models in sklearn, PyTorch, TensorFlow, or whatever frameworks you’ve used, instead of compiling your models to run on specific hardware, you can compile your model to WASM. You get back an executable file that you can just use with JavaScript.
The main drawback of WASM is that because WASM runs in browsers, it’s slow. Even though WASM is already much faster than JavaScript, it’s still slow compared to running code natively on devices (such as iOS or Android apps). A study by Jangda et al. showed that applications compiled to WASM run slower than native applications by an average of 45% (on Firefox) to 55% (on Chrome).
There are many compilers that help you compile into WASM runtime. The most popular one is probably Emscripten (which also uses LLVM codegen), but it only compiles from C and C++ into WASM. scailable is supposed to convert from scikit-learn models into WASM, but it has only 13 stars on GitHub and no update in the last 3 months (is it even being maintained?). TVM is the only active compiler that I know of that compiles from ML models into WASM. If you know of any other compilers, let me know and I’d love to add them here!
Tip: If you decide to try out TVM, use their unofficial conda/pip command for fast installation instead of the instructions found on the Apache site. They only have a Discord server if you need help!
7. What's next for compilers
It’s helpful to think of how your models run on different hardware backends so that you can improve their performance. Austin Huang posted on our MLOps Discord that he often sees 2x speedup by just using simple off-the-shelf tools (quantization tools, Torchscript, ONNX, TVM) without much effort.
Here’s a great list of tips that can help you speed up PyTorch models on GPUs without even using compilers.
When your model is ready for deployment, it makes sense to try out different compilers to see which one gives you the best performance boost. You can run the experiments in parallel. A small boost for one inference request can accumulate into big returns over millions or billions of inference requests.
Even though there has been huge progress in compilers for machine learning, there’s still a lot of work to be done before we can abstract compilers completely from general ML practitioners. Think about traditional compilers like GCC. You write your code in C or C++, and GCC automatically lowers your code into machine code. Most C programmers don’t even care what the intermediate representations GCC generates.
In the future, ML compilers can be the same way. You use a framework to create an ML model in the form of a computation graph, and your ML compiler can generate machine-native code for whatever hardware you run on. You won’t even need to worry about intermediate representations.
Tools like TVM are steps towards making that future possible.
Acknowledgments
I’d like to thank Luke Metz, Chris Hoge, Denise Kutnick, Parimarjan Negi, Ben Schreiber, Tom Gall, Nikhil Thorat, Daniel Smilkov, Jason Knight, and Luis Ceze for patiently answering my hundreds of questions and making this post possible.