Top 8 trends from ICLR 2019
[Twitter thread] Disclaimer: This post doesn’t reflect the view of any of the organizations I’m associated with and is probably peppered with my personal and institutional biases. The Reinforcement Learning section was written by my wonderful intern and colleague Oleksii Hrinchuk.
1. Inclusivity
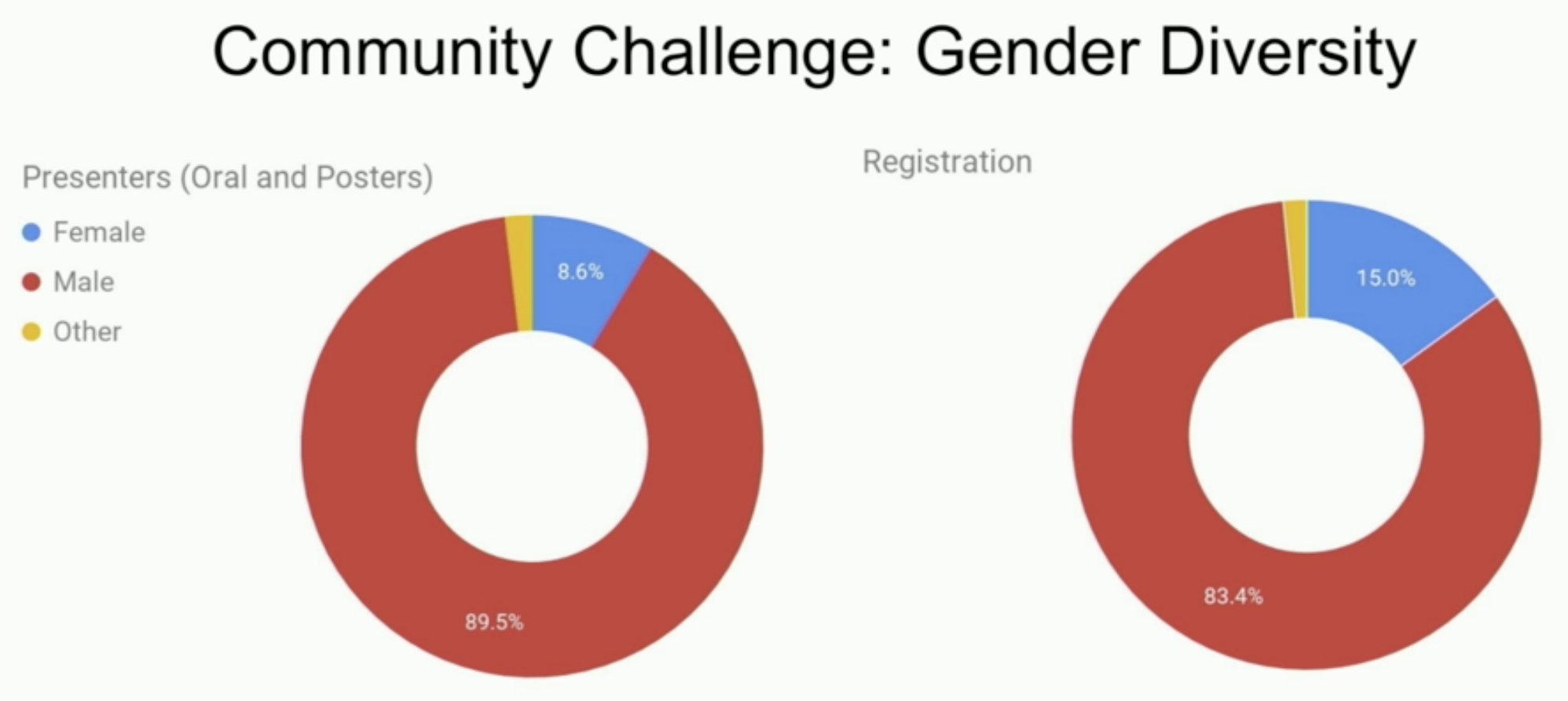
The organizers pressed the importance of inclusivity in AI by making sure that the first two main talks, the Sasha Rush’s opening remarks and Cynthia Dwork’s invited talk, were about fairness and equality. Some of the worrisome statistics include:
- Only 8.6% of presenters and 15% of participants are women.
- 2/3rd of all the LGBTQ+ researchers aren’t out professionally.
- All 8 invited speakers are white.
Unfortunately, it still feels like the average AI researcher is unapologetically disinterested. While all other workshops were oversubscribed, the AI for Social Good workshop was pretty empty until Yoshua Bengio showed up. During the multitude of conversations I had at ICLR during, no one ever mentioned diversity except that one time I wondered out loud why I was invited to this one tech event that I didn’t seem to fit in and a good friend said: “A somewhat offensive answer would be because you’re a woman.”
One reason is that the topic isn’t “technical”, and therefore spending time on it won’t help advancing your career in research. Another is that there’s still some stigma against social advocacy. A friend once told me to ignore a dude who was trolling me in a group chat because “he likes to make fun of people who talk about equality and diversity.” I have friends who wouldn’t discuss anything on diversity online because they don’t want to be “associated with that kind of topic.”
2. Unsupervised representation learning & transfer learning
A major goal of unsupervised representation learning is to discover useful data representations from unlabeled data to use for subsequent tasks. In Natural Language Processing, unsupervised representation learning is often done with language modeling. The representations learned are then used for tasks such as sentiment analysis, name entity recognition, and machine translation.
Some of the most exciting papers coming out in the last year are about unsupervised representation learning in natural language processing, starting with ELMo (Peters et al.), ULMFiT (Howard et al.), OpenAI’s GPT (Radford et al.), BERT (Devlin et al.), and of course, the too-dangerous-to-be-released GPT-2 (Radford et al.).
The full GPT-2 model was demoed at ICLR and it’s terrifyingly good. You can enter almost any prompt and it’d write the rest of the article. It can write buzzfeed articles, fanfiction, scientific papers, even definitions of made-up words. But it doesn’t sound entirely human yet. The team is working on GPT-3, bigger and hopefully better. I can’t wait to see what it can produce.
While the computer vision community is the first to get transfer learning to work, the base task – training a classification model on ImageNet – is still supervised. A question I keep hearing from researchers in both communities is “How can we get unsupervised representation learning to work for images?”
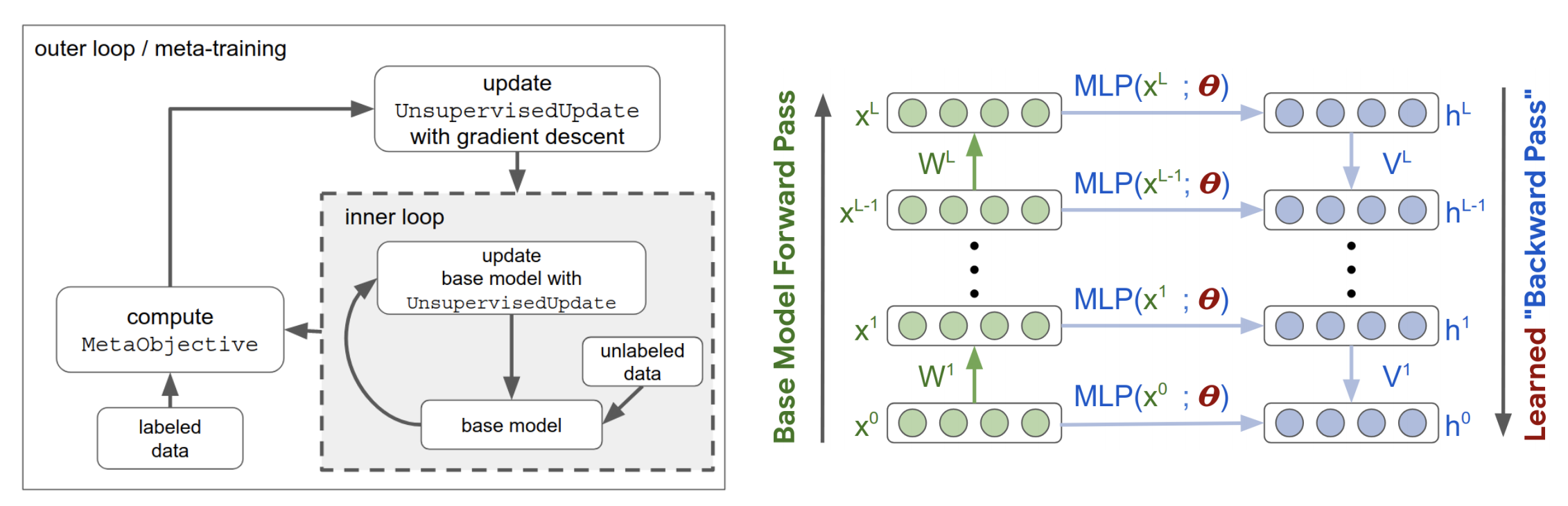
Even though most big-name research labs are already working on it, there’s only one paper presented at ICLR: “Meta-Learning Update Rules for Unsupervised Representation Learning” (Metz et al.). Instead of updating the weights, their algorithm updates the learning rule. The representations learned from the learned learning rule is then fine-tuned on a small number of labeled samples for the task of image classification. They were able to find learning rules that achieved accuracy > 70% on MNIST and Fashion MNIST.
The authors have part of the code public but not all of it because “it’s tied to the compute.” The outer loop requires about 100k training steps and 200 hours on 256 CPUs.
I have a feeling that we will see a lot more papers like this in the near future. Some of the tasks that can be used for unsupervised learning include: autoencoding, predicting image rotations (this paper by Gidaris et al. was a hit at ICLR 2018), predicting the next frame in a video.
3. Retro ML
Ideas in machine learning are like fashion: they go around in a circle. Walking around the poster sessions is like taking a stroll down the memory lane. Even the highly-anticipated ICLR debate ended up being about priors vs structure, which is a throwback to Yann LeCun and Christopher Manning’s discussion last year and weirdly resembles the age-old debate between Bayesians and frequentists.
The Grounded Language Learning and Understanding project at the MIT Media Lab was discontinued in 2001, but grounded language learning made a comeback this year with two papers, dressed in the clothes of reinforcement learning.
- DOM-Q-NET: Grounded RL on Structured Language (Jia et al.) - an RL algorithm to learn to navigate webs by filling up fields and clicking links, given a goal expressed in natural language.
- BabyAI: A Platform to Study the Sample Efficiency of Grounded Language Learning (Chevalier-Boisvert et al.) - an OpenAI Gym-compatible platform with a hand-crafted bot agent that simulates a human teacher to guide agents in learning a synthetic language.
My thoughts on these two papers are perfectly summarized by AnonReviewer4:
“… the methods proposed here look very similar to methods that have been studied for quite a while in the semantic parsing literature. Yet this paper only cites recent deep RL papers. I think the authors would benefit greatly from familiarizing themselves with this literature. I think the semantic parsing community would also benefit from this … But the two communities don’t really talk to each other much, it seems, even though in some cases we are working on very similar problems.”
Deterministic Finite Automata (DFA) also found its place in the world of deep learning this year with two papers:
- Representing Formal Languages: A Comparison Between Finite Automata and Recurrent Neural Networks (Michalenko et al.)
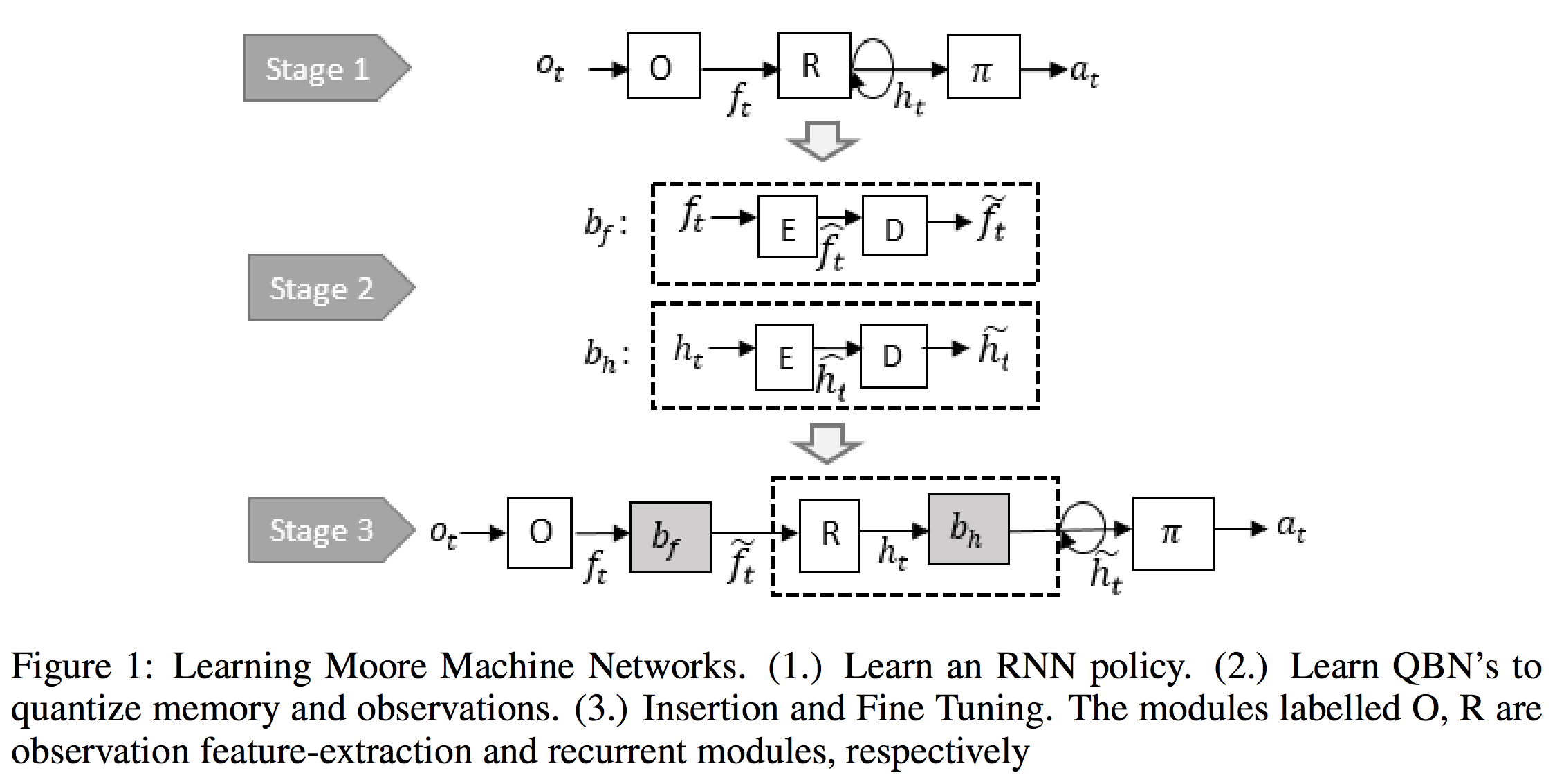
- Learning Finite State Representations of Recurrent Policy Networks (Koul et al.)
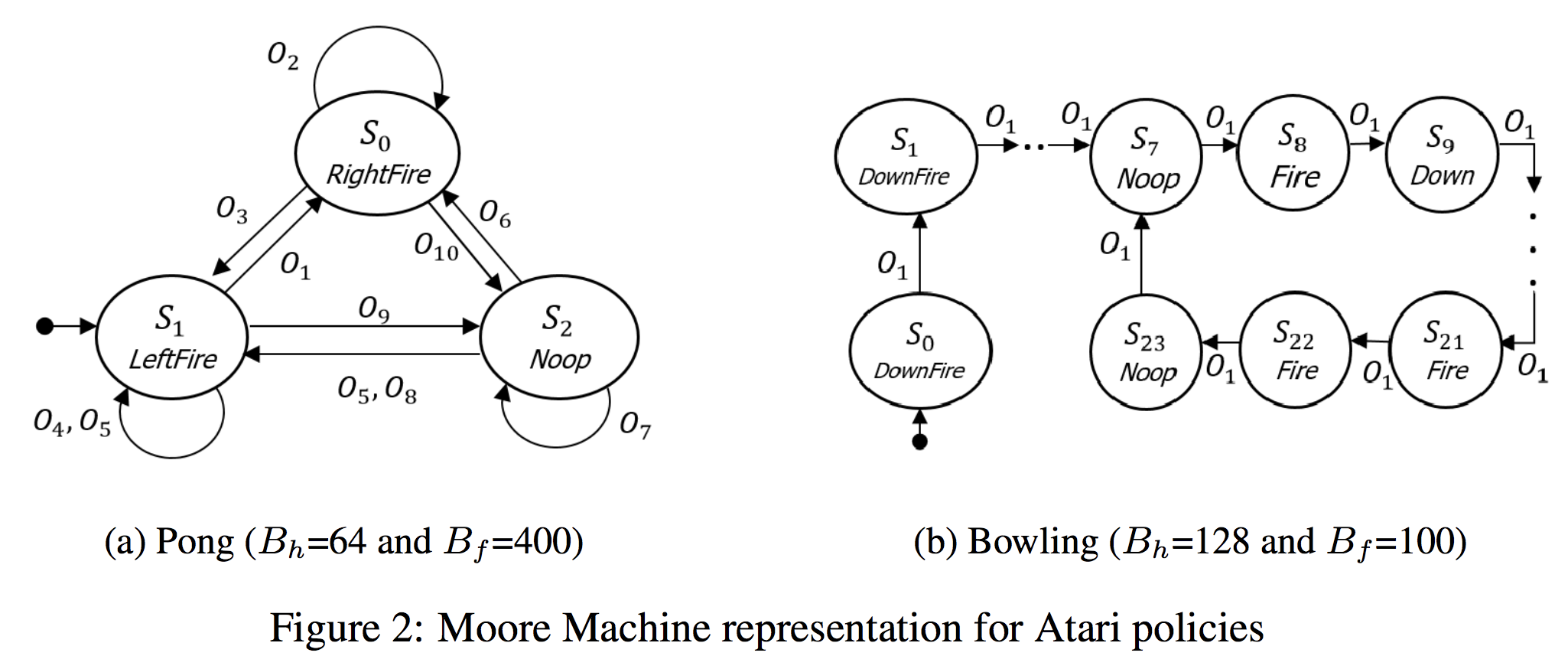
The main motivation behind both papers is that since the space of hidden states in RNNs is enormous, is it possible to reduce the number of states into a finite number of states? I’m skeptical that DFA can effectively represent RNNs for languages, but I really like the idea of learning RNNs during training and then converting it into DFA for inference, as presented in Koul et al.’s paper. The resulting finite representations require as few as 3 discrete memory states and 10 observations for the game of Pong. The finite state representation also help with interpreting RNNs.
4. RNN is losing its luster with researchers
The relative change in submission topics from 2018 to 2019 shows that RNN takes the biggest dip. This isn’t surprising because while RNNs are intuitive for sequential data, they suffer from a massive drawback: they can’t be parallelized and therefore can’t take advantage of the biggest factor that has driven progress in research since 2012: compute power. RNNs have never been popular in CV or RL, and for NLP, they are being replaced by attention-based architectures.
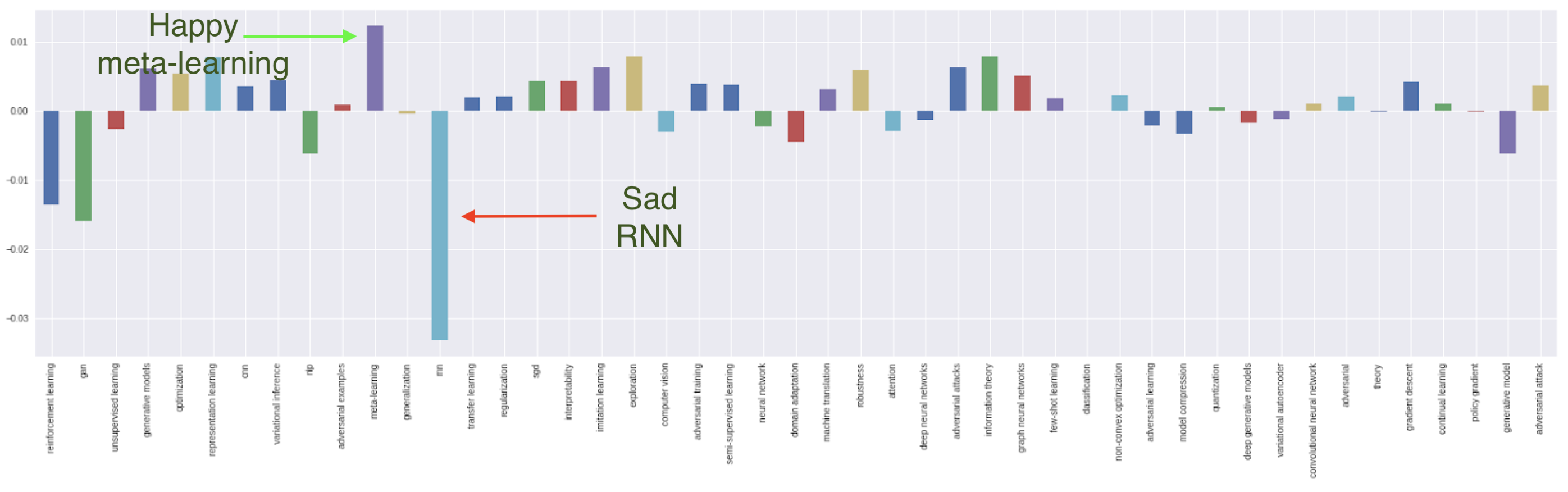
Does that mean that RNN is dead? Not really. One of the two best paper awards this year is for “Ordered neurons: Integrating tree structures into Recurrent Neural Networks.” (Shen et al.). Other than this paper and two on automata mentioned above, there are nine more papers on RNNs accepted this year, most of them dig deep into the mathematical foundations of RNNs instead of discovering new applications for RNNs.
RNNs are still very alive and kicking in the industry, especially for companies that deal with time-series data such as trading firms, and these firms, unfortunately, don’t usually publish their work. Even if RNN is unattractive to researchers right now, who knows it might make a comeback in the future.
5. GANs are still going on strong
Even though GAN takes a negative relative change compared to last year, the number of papers actually went up, from ~70 to ~100. Ian Goodfellow delivered a popular invited talk on GAN and was constantly mobbed by admirers. By the last day, he had to flip his badge so that people wouldn’t see his name.
The entire first poster session was dedicated to GANs. There are new GAN architectures, improvements on old GAN architecture, GAN analyses, GAN applications from image generation to text generation to audio synthesis. There are PATE-GAN, GANSynth, ProbGAN, InstaGAN, RelGAN, MisGAN, SPIGAN, LayoutGAN, KnockoffGAN, etc. and I have no idea what any of these means because I’m illiterate when it comes to GAN literature. I’m also sorely disappointed that Andrew Brock didn’t call his large scale GAN model giGANtic.

The GAN poster session reveals just how polarized the community is when it comes to GAN. Some of the comments I’ve heard from non-GAN peeps include: “I can’t wait for all this GAN thing to blow over”, “As soon as somebody mentions adversarial my brain just shuts down.” For all I know, they might just be jealous.
6. The lack of biologically inspired deep learning
Given all the fuss about gene sequencing and CRISPR babies, it’s surprising that there aren’t more papers on deep learning in biology at ICLR. There are a grand total of six papers on the topic:
Two on biologically-inspired architectures
- Biologically-Plausible Learning Algorithms Can Scale to Large Datasets (Xiao et al.)
- A Unified Theory of Early Visual Representations from Retina to Cortex through Anatomically Constrained Deep CNNs (Lindsey et al.)
One on Learning to Design RNA (Runge et al.)
Three on protein manipulation:
- Human-level Protein Localization with Convolutional Neural Networks (Rumetshofer et al.)
- Learning Protein Structure with a Differentiable Simulator (Ingraham et al.)
- Learning protein sequence embeddings using information from structure (Bepler et al.)
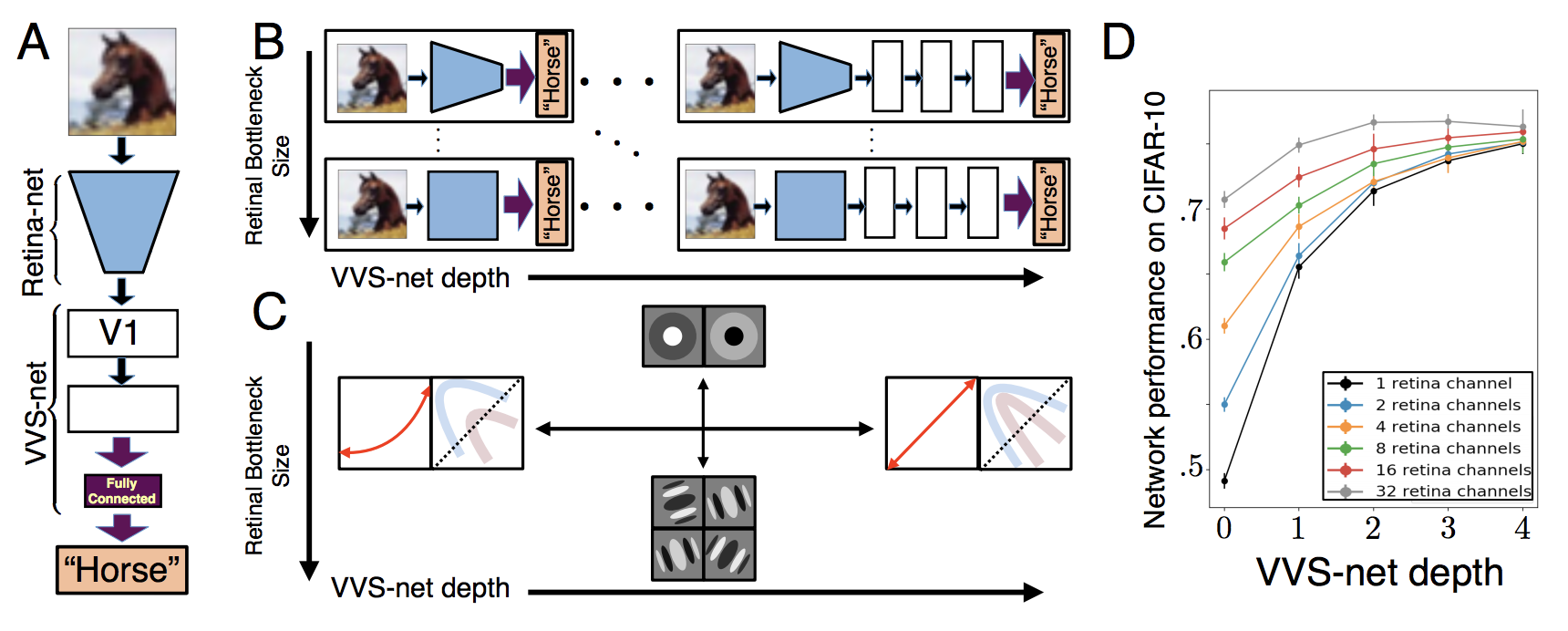
There’s zero paper on genomics. Neither was there any workshop on the topic. It’s sad but it also shows a huge opportunity for deep learning researchers who are interested in biology or biologists who are interested in deep learning.
Random fact: the first author of the retina paper, Jack Lindsey, is still a senior in college (Stanford). Kids these days urrggh.
7. Reinforcement learning is still the most popular topic by submissions
Works presented at the conference indicate that the RL community is moving from model-free methods to sample-efficient model-based and meta-learning algorithms. The shift was likely motivated by extremely high scores on Mujoco continuous control benchmarks set by TD3 (Fujimoto et al., 2018) and SAC (Haarnoja et al., 2018), and on Atari discrete control tasks set by R2D2 (Kapturowski et al., ICLR 2019).
Model-based algorithms – which learn a model of the environment from data and exploit it to plan or generate more data – have finally reached the asymptotic performance of their model-free counterparts while using 10-100x less experience (MB-MPO (Rothfuss et al.)). This advantage makes them suitable for real-world tasks. While a single learned simulator is likely to be flawed, its errors can be mitigated with more complex dynamics models, such as an ensemble of simulators (Rajeswaran et al.). Another way to apply RL to real world problems is to allow the simulator to support arbitrarily complex randomizations: the policy trained on a diverse set of simulated environments might consider the real world as “yet another randomization” and succeed in it (OpenAI).
Meta-learning algorithms which perform fast transfer learning among multiple tasks have also improved a lot both in terms of sample-efficiency and performance (ProMP (Rothfuss et al.), PEARL (Rakelly et al.)). These improvements brought us closer to “the ImageNet moment of RL” when we may use control policies learned from other tasks instead of training them from scratch (which is impossible for complex tasks).
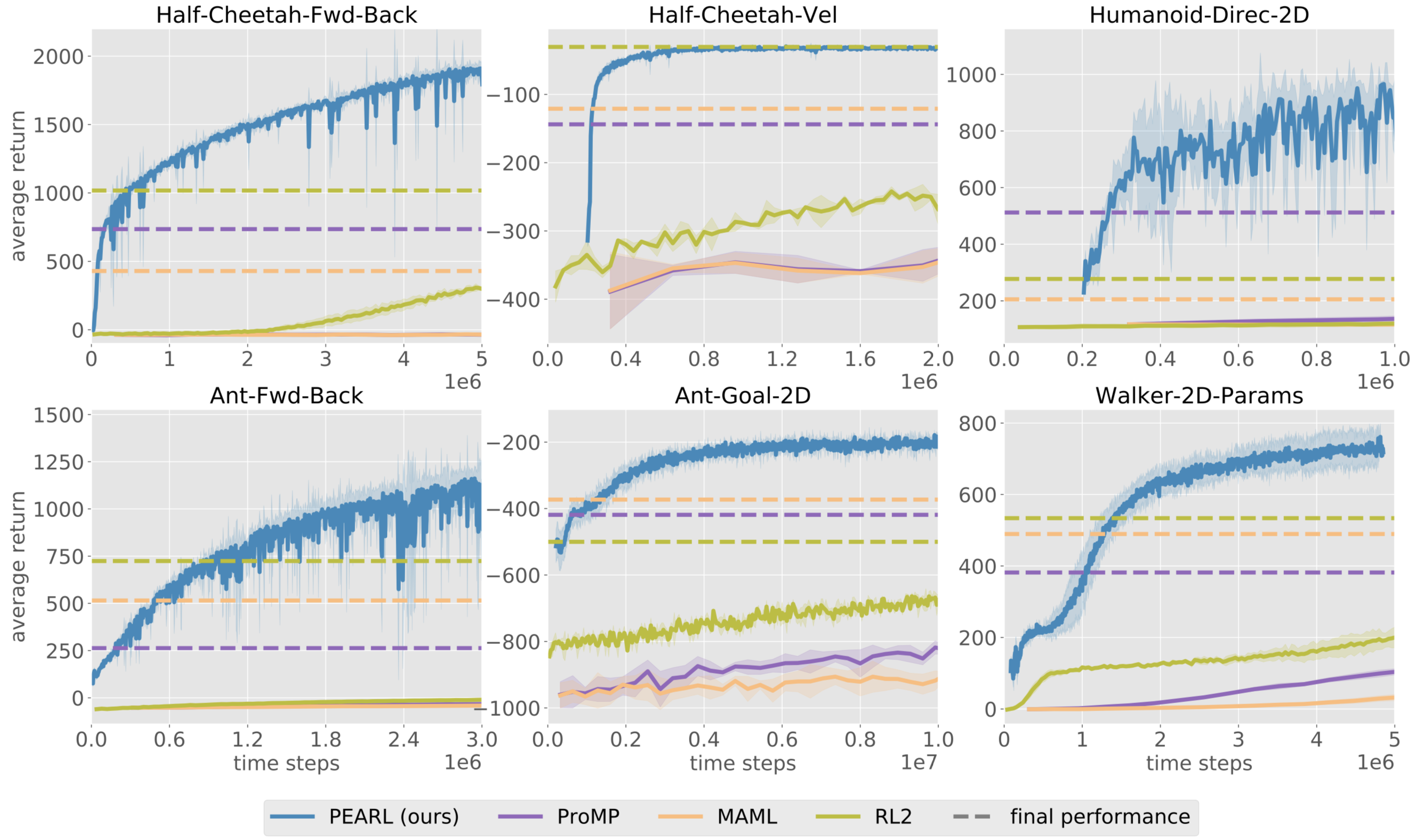
A large portion of accepted papers, together with the entire Structure and Priors in RL workshop, was devoted to integrating some knowledge about the environment into the learning algorithms. While one of the main strengths of early deep RL algorithms was generality (e.g. DQN uses the same architecture for all Atari games without knowing anything about any particular game), new algorithms show that incorporating prior knowledge helps with more complex tasks. For example, in Transporter Network (Jakab et al.), the agent uses prior knowledge to conduct more informative structural exploration.
To sum up, during the last 5 years, the RL community has developed a variety of efficient tools for solving RL problems in a model-free setup. Now it’s time to come up with more sample-efficient and transferable algorithms to apply RL to real world problems.
Random fact: Sergey Levine is probably the person with the most papers at ICLR this year with 15 accepted papers.
8. Most accepted papers will be quickly forgotten
When I asked a well known researcher what he thinks of the accepted papers this year, he chuckled: “Most of them will be forgotten as soon as the conference is over.” In a field moving as fast as machine learning where state-of-the-art results are broken after weeks, if not days, it’s not surprising that most accepted papers are already outperformed by the time they are presented. For example, according to Borealis AI, for ICLR 2018, “seven out of eight defense papers were broken before the ICLR conference even started.”
One comment I frequently heard during the conference is how random the acceptance/rejection decisions are. I won’t name any but some of the most-talked about/most cited papers in the last few years were rejected from the conferences they were originally submitted to. Yet, many of the accepted papers will go on for years without ever being cited.
As someone doing research in the field, I frequently face existential crisis. Whatever idea I have, it seems like someone else is already doing it, better and faster. What’s the point of publishing a paper if it’ll never be of any use to anyone? Somebody help!
Conclusion
There are definitely more trends I’d like to cover such as:
- optimizations and regularizations: The Adam vs SGD debate is continued. Many new techniques are proposed and some are quite exciting. It seems like every lab is developing their own optimizer these days – even our team is working on a new optimizer that should be released soon.
- evaluation metrics: As generative models become more and more popular, it’s inevitable that we need to come up with some metrics to evaluate generated outputs. Metrics for generated structured data are questionable enough, but metrics for generated unstructured data such as open-domain dialogues and GAN-generated images are uncharted territory.
However, the post is getting long and I need to get back to work. If you want to learn more, David Abel published his detailed notes (55 pages). For those who want to see what else is hot at ICLR 2019, I found this graph from ICLR 2019’s supplementary statistics particularly indicative.
I really enjoyed ICLR. The conference is big enough to find many people to have interesting conversations with yet small enough to not have to wait in line for things. The length of the conference, 4 days, is also just right. NeurIPS is a bit too long and usually by the end of the fourth day, I’d be walking by posters and thinking: “Look at all the wonderful knowledge I could be acquiring right now but don’t want to.”
The biggest takeaway I got from the conference is not just ideas, but also motivation. Seeing researchers my age doing wonderful things helps me see the beauty of research and motivates me to work hard myself. It’s also nice to have an entire week to catch up on papers and old friends. 10/10 would recommend.