SOTAWHAT - A script to keep track of state-of-the-art AI research
While doing research, I often find myself wondering: “What’s the state-of-the-art result for XYZ right now?” I just want a tool that returns the summary of the latest SOTA research. My usual go-to place is Google, but I quickly realize that Google often returns:
- papers that have a lot of citations, which means they are old.
- articles that discuss SOTA systems. Again, these articles can be a couple of years old.
- irrelevant results that share the same name as XYZ.
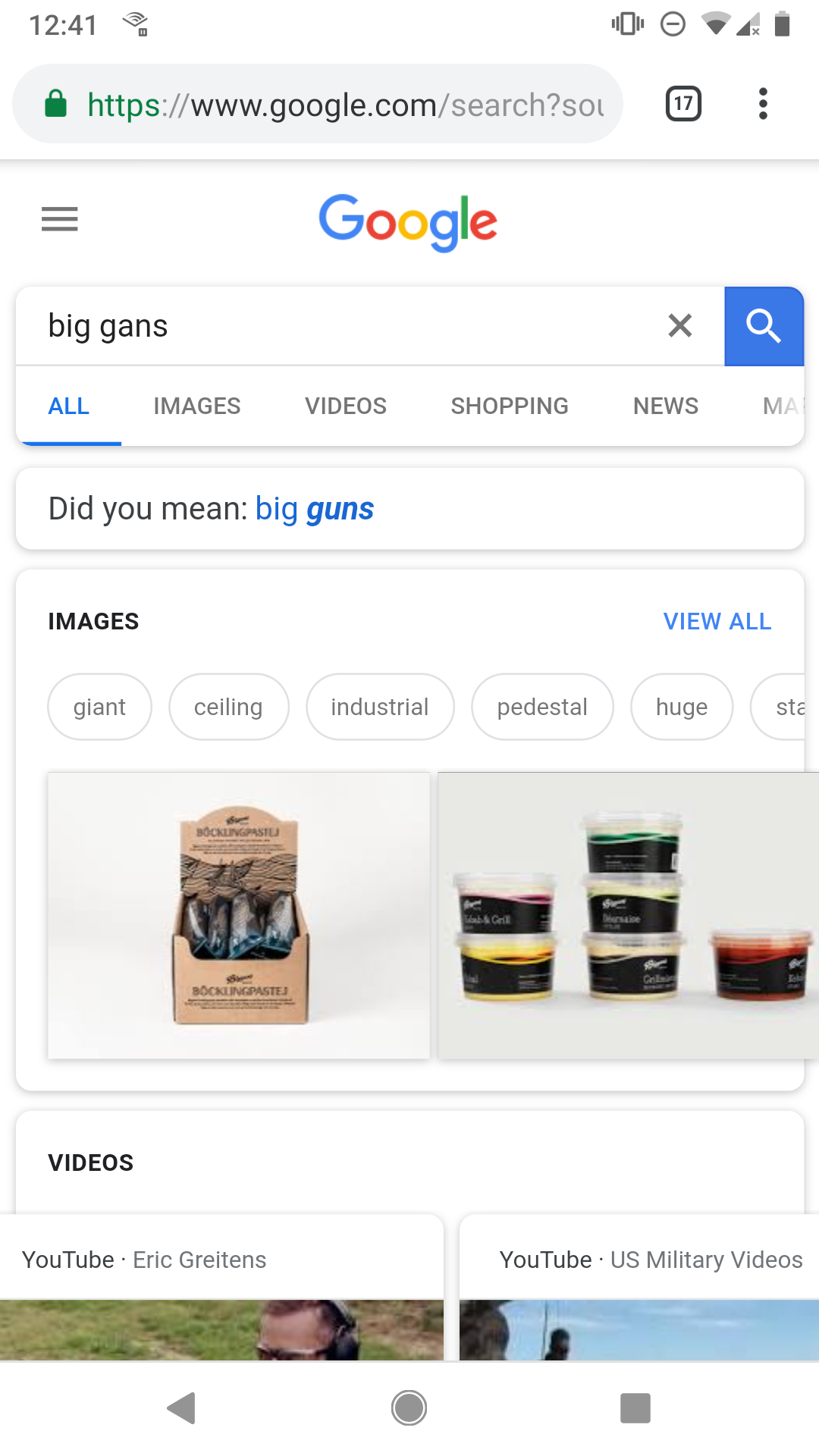
At best, I have to skim those results. At worst, I don’t find what I’m looking for at all (I might if I go to the next page results but who does that?) Some examples:
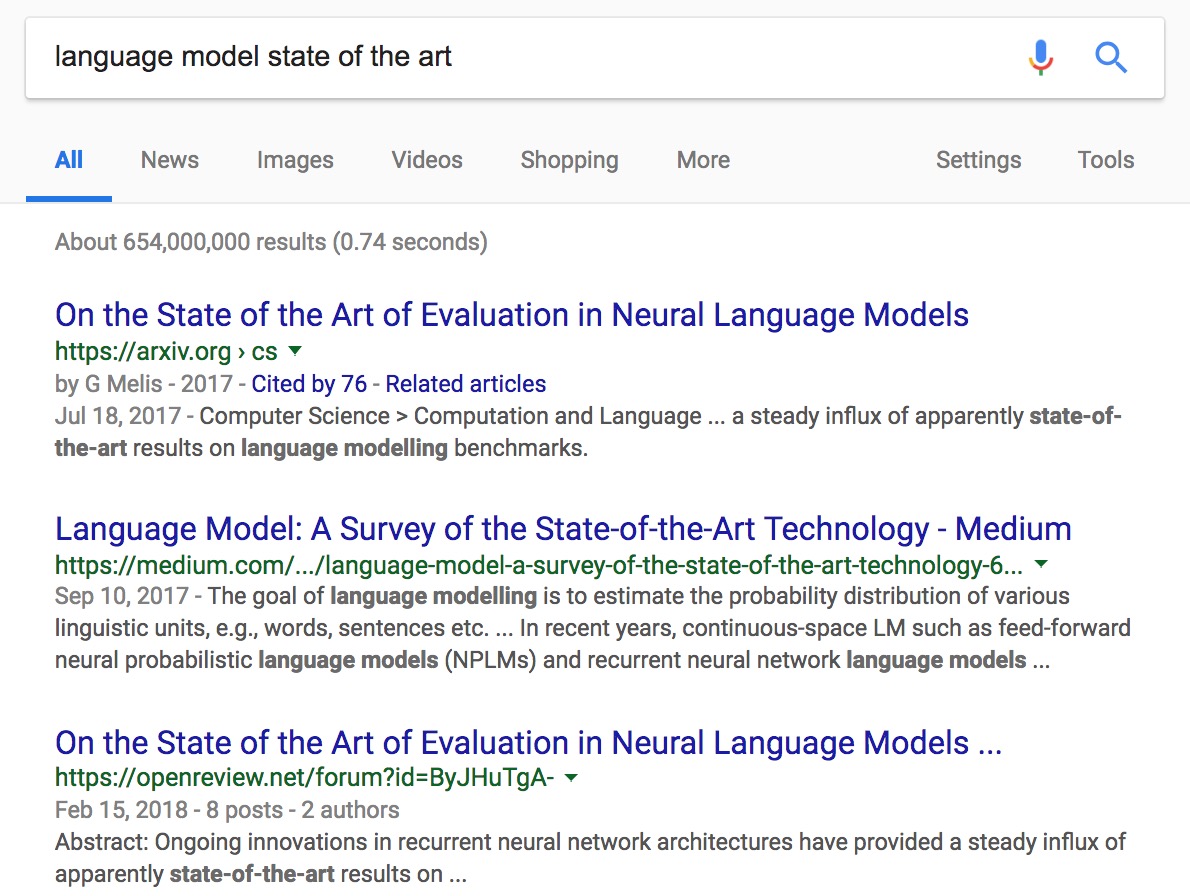
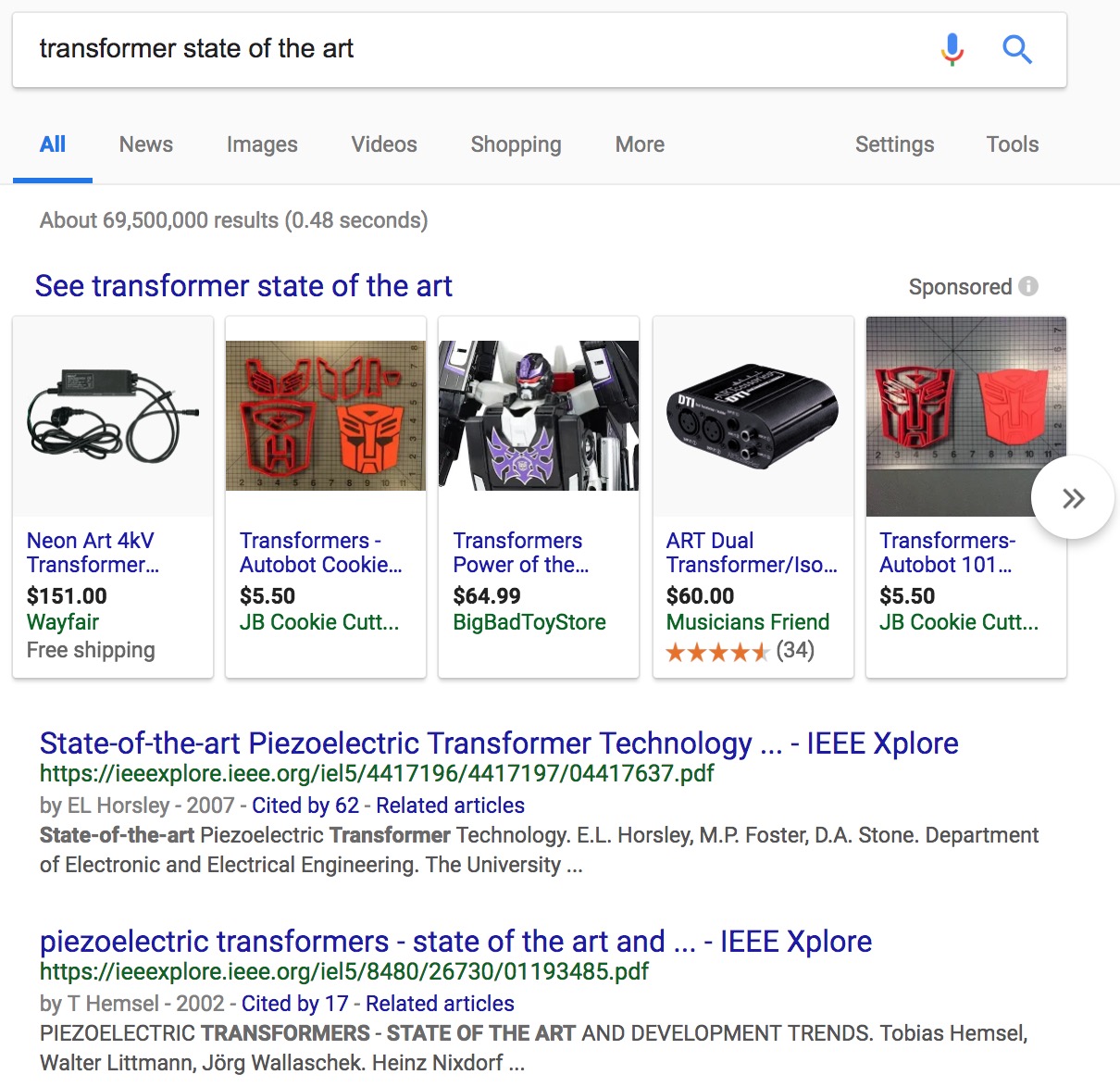
And my personal favorite:
My next stop is Arxiv. Just for the record, I love Arxiv. But their search isn’t that good. For one thing, if you search “Transformer”, it’ll return all results that contain words of the same root including “transformation”, “transforms”, “transformed”. For another, it only shows the first half of the abstracts. You have to click to show more and skim to find relevant numbers.
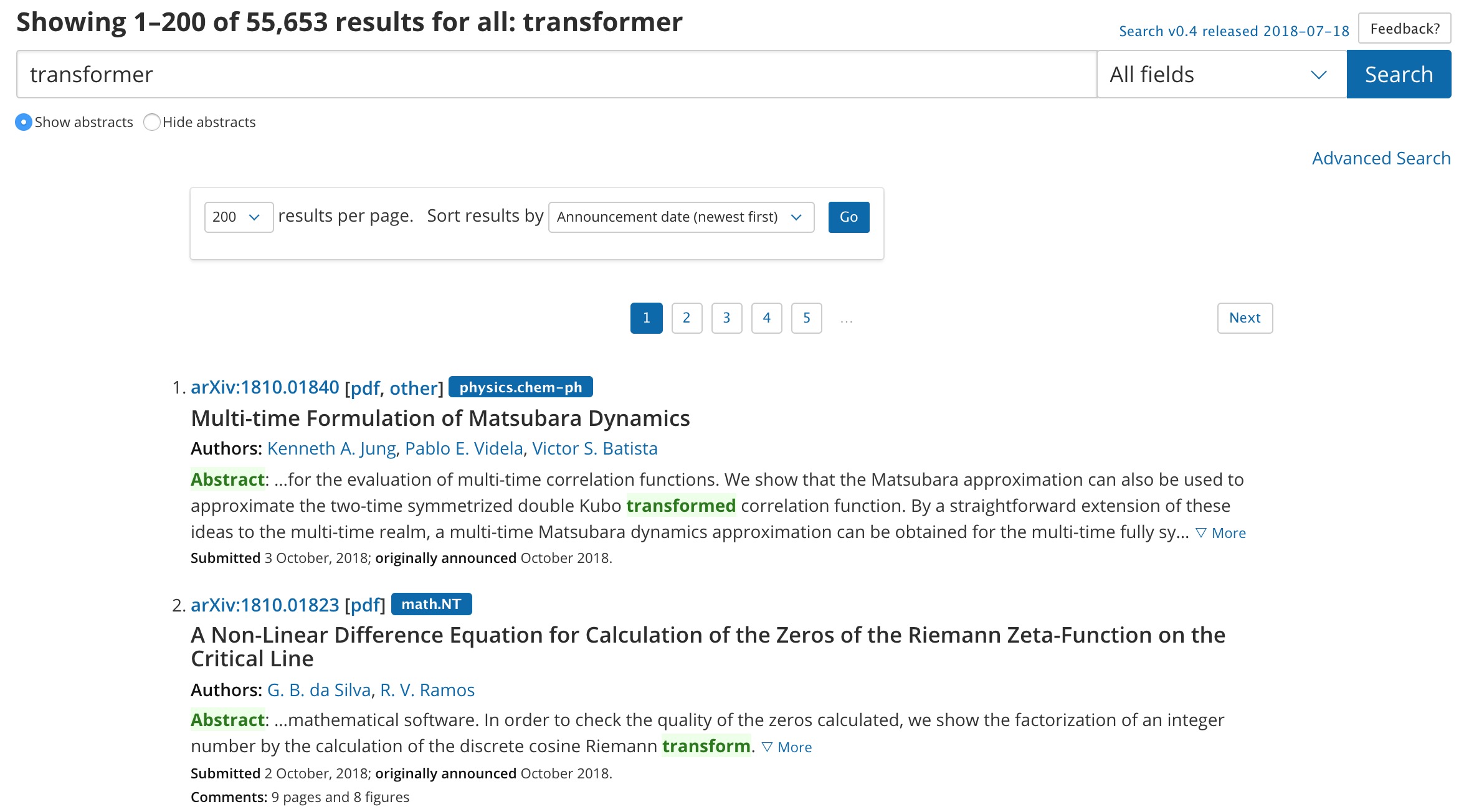
So last week, while waiting for my roommates to warm up their pizza, I decided to write a script to query arxiv for abstracts that contain a specific keyword and return summaries of those abstracts. Some implementation details:
- I query arxiv directly instead of using their API because their export links somehow don’t return all the results.
- I prioritize abstracts that contain numbers and extract sentences that contain numbers. I mean, if I’m looking for the SOTA perplexity for language models, I just want to see the numbers.
- Each summary contains the paper’s title, first author, date of publication, abstract’s summary, and the link to the paper.
- The script is slow (a few seconds wait) because arxiv server takes a long time to response.
- It currently only works with python3 but I’ve received a request to make it compatible with python2.
The script is simple (283 lines of code) and requires 2 packages (nltk and PyEnchant). I was pleasantly surprised when I queried for a few keywords and it returned exactly what I needed. A couple of my friends at Nvidia, Facebook, and Google tried it and they told me they found it useful. A friend told me that the code was too simple and that I should throw some machine learning into it to get people interested. Talk about machine learning hype.
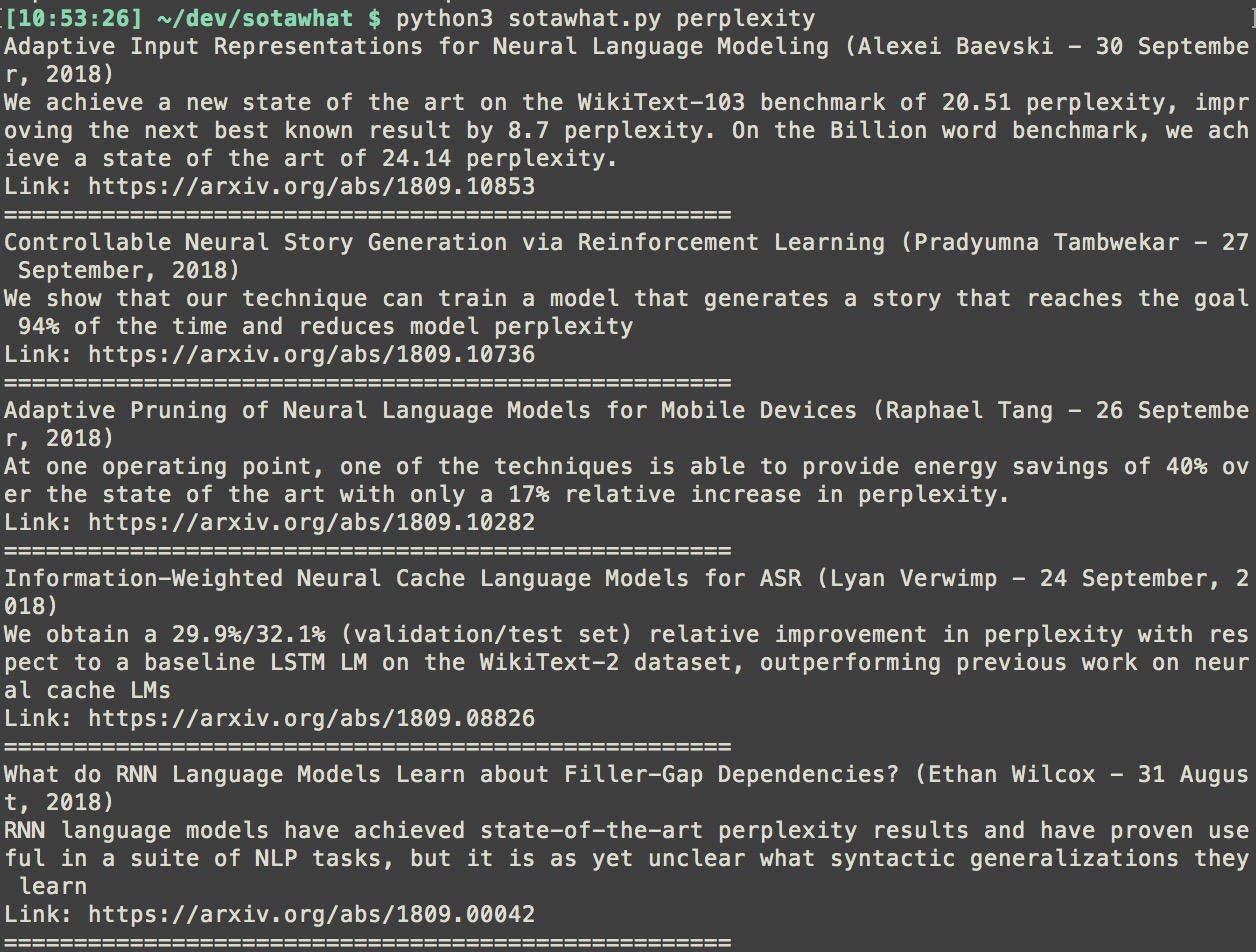
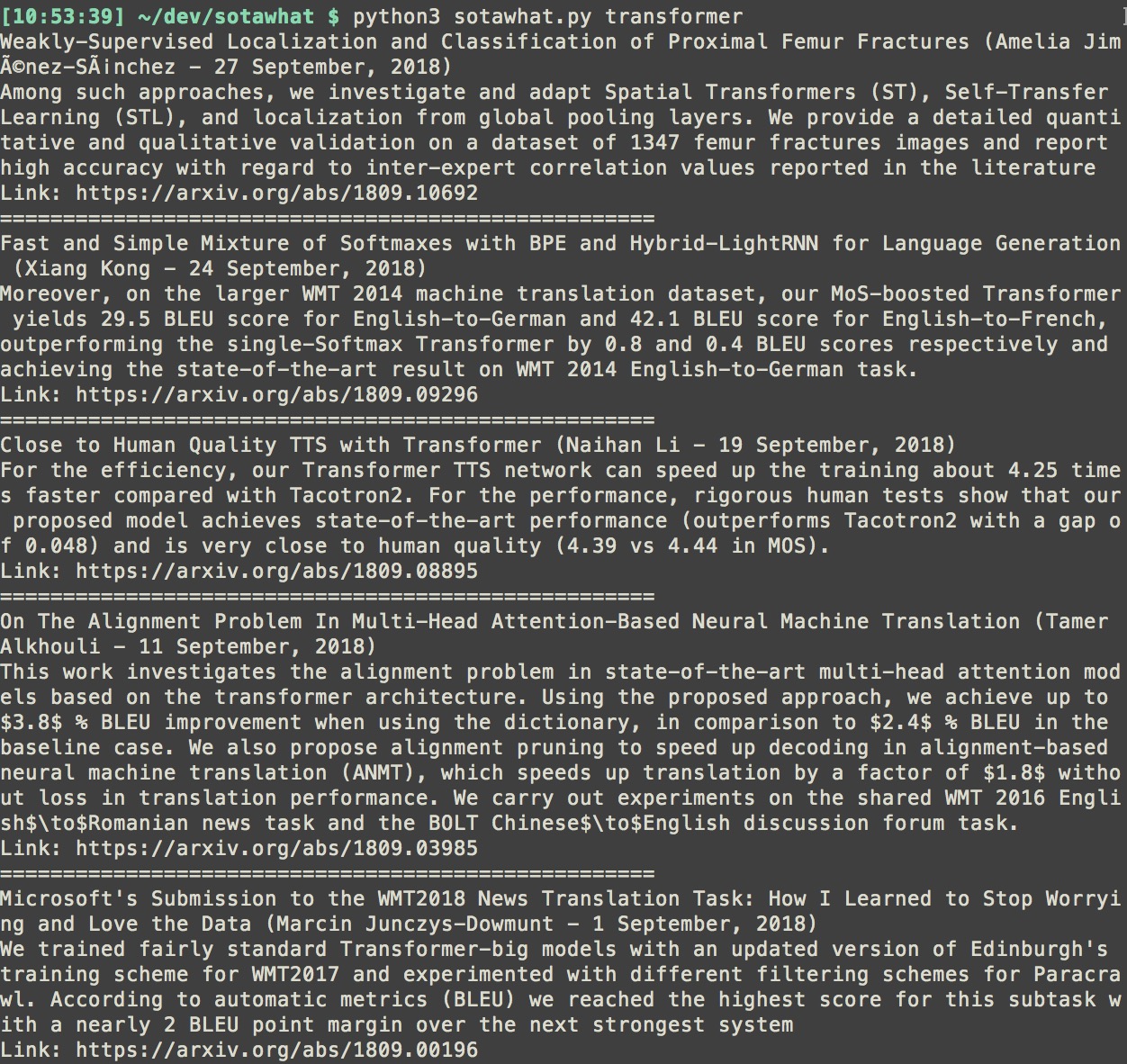
You can download the script and find the instruction on my GitHub here. Feedback is welcome!